
 MDW Architecture
MDW ArchitectureThis chapter discusses:
Multidimensional Warehouse (MDW) architecture.
MDW composition.
MDW dimensions.
MDW facts.
MDW setup.
Moving data into the MDW.
MDW ArchitectureEPM Foundation contains two functional layers:
The Operational Warehouse layer, which contains the normalized structures.
The Operational Warehouse is made up of two functional areas:
Operational Warehouse Staging (OWS), to which source data is moved.
Operational Warehouse Enriched (OWE), which stores enriched data generated for warehouse business units.
The OWE is used primarily by PeopleSoft analytic applications.
The MDW, which contains the dimensional schema for business intelligence and ad hoc reporting.
The data in the MDW is stored in the form of star schemas and generally contains data loaded from the OWS.
Note. Although data loaded into the MDW primarily comes from the OWS, there are exceptions to this rule. Profitability and Global
Consolidations data for the Financials Warehouse is loaded into the MDW from the OWE.
External survey data for the HCM Warehouse is loaded into the MDW from the OWE.
CRM Online Marketing data is loaded into the MDW directly from the source system and bypasses the Operational Warehouse entirely.
See Understanding PeopleSoft Enterprise Performance Management (EPM) Foundation.
MDW CompositionThe MDW layer is built on the principle of dimensional modeling. Using this principle, data is grouped as it is related to one or more business processes. The data is primarily stored in a star schema—that is, a fact table surrounded by a series of dimension tables.
This graphic presents an example of a fact table and related dimension tables in a star schema.
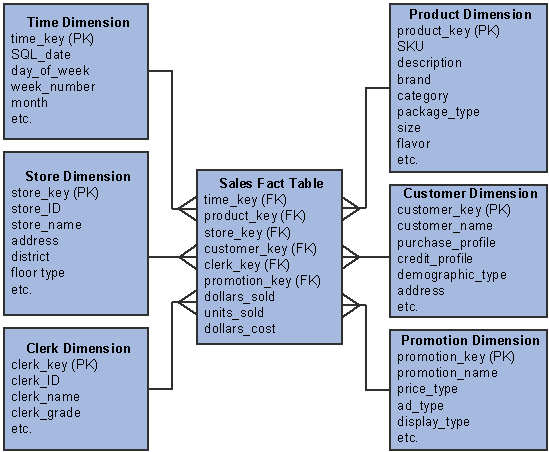
This section discusses:
Surrogate key generation.
Audit fields.
Data aggregation.
Surrogate Key GenerationSurrogate keys provide a means of defining unique keys whose values, with the exception of the Time and Calendar dimensions, are anonymous; that is, the value of a surrogate key has no significance to the application using it and is strictly an artificial value. The system uses surrogate keys specifically as a means of joining structures. To speed up query access, the MDW resolves PeopleSoft-specific programming constructs, such as SetIDs and effective dates, and replaces them with surrogate IDs as key columns.
Surrogate keys are generated from production keys by an extract, transform, and load (ETL) mapping process and have no relationship to the business or production key. Surrogate keys are present in dimension tables as the primary key and in fact tables as foreign keys to dimensions. However, the dimension record retains the business key as an alternate-key attribute. Surrogate keys are four-byte integers and their size does not change, even when production key changes in size.
Although surrogate keys usually do not have any “intelligence,” that is, their value has no meaning, in certain situations, such as the Gregorian Calendar and Time dimensions, intelligent surrogate keys are used. These intelligent keys allow the ETL process to run more quickly by providing the option of avoiding a lookup on corresponding dimensions.
Surrogate keys can be unique within a database or unique within each dimension table. You configure this feature by the value you give to the environment parameter SID_UNIQUENESS. Surrogate key fields usually have the suffix _SID (Surrogate ID).
Surrogate keys provide benefits such as:
The ability to easily and structurally conform a dimension when being sourced from multiple systems.
Disassociation from operational system changes.
Because surrogate key generation is controlled by the warehouse, it is not influenced by operational system changes.
The ability to handle unspecified or missing key values.
A graceful mechanism to handle changes in history.
Multiple versions of a dimension can be maintained with different surrogate (primary) keys, yet with the same business (identifying) key.
Performance enhancement of queries.
Because surrogate key is a single column numeric key, the joins using surrogate keys are faster than ones using multi-column business keys.
You do not have to take any action to create surrogate keys; they are created automatically during ETL. They are generated during the ETL process within DataStage routines. The DataStage routine retrieves the next surrogate key value and assigns it to the surrogate key that it is currently creating. When the ETL process copies a dimension row from the source system into the MDW, the ETL process performs a lookup on the dimension table. If the dimension row (with same business keys) does not exist in the dimension table, the process inserts a row with a new surrogate key value. If the dimension row already exists in the dimension table, the process updates the existing row with the incoming row value. When the ETL process copies a fact row from the source system into the MDW, for each dimension key in the fact row, the system performs a lookup on the dimension table and retrieves the corresponding surrogate key value. This surrogate key is the foreign key value in the fact row in the MDW. If the system does not locate a dimension value in the fact row in the dimension table, that is a data exception and an error results.
Audit FieldsAudit fields track ETL loading information, such as when the row was loaded or last modified or the batch in which the row was loaded. This information is included in a subrecord. Although all OWS and MDW tables have a subrecord, only OWE tables that are loaded from the OWS using ETL have subrecords. OWE tables that are loaded by enrichment engines using other OWE tables typically do not have subrecords. The subrecord added to MDW tables is named LOAD_MDW_SBR. Subrecords are always added at the end of a record; no fields exist after this subrecord in any table.
The following example shows a typical LOAD_MDW_SBR record.
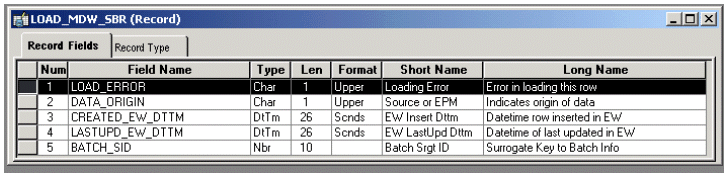
LOAD_MDW_SBR record example
Data AggregationTables in the MDW contain source data at the same granularity as the source system. Required data aggregation is carried out at run time by the business intelligence tool. This allows for better control of aggregation strategies by the business intelligence tool, because aggregation requirements vary from customer to customer.
MDW DimensionsDimension tables contain surrogate keys as the primary key and are a single column key containing only the surrogate key column. Surrogate keys usually have _SID (surrogate ID) appended to the field name. Dimension tables retain source system business key fields as non-key attribute columns in the dimension table. However, they are not used for joins with fact tables. For example, in the Customer dimension, the original business key field CUST_ID is retained, if it exists in the source table, but is no longer included in the dimension key. The SetID is also retained, if it exists in the source table, as a non-key attribute; the value contained in the SetID is the same as in the source system.
If a dimension is SetID-based, the MDW table contains the source SetID and the performance (PF) SetID, which is named SETID.
If a dimension contains a description text field, a related language table is often defined for this dimension. The ETL process populates this table if a customer requires multilanguage processing. The key for this table is the surrogate key ID, plus the language code field, LANGUAGE_CD, which contains the code for the additional language.
See Setting Up Multilanguage Processing.
Conformed DimensionsConformed dimensions are either exactly the same, including key structure, or an exact subset of another dimension, That is, conformed dimensions are structurally identical every place in which they are used. When using a conformed dimension, the system consistently interprets its attributes; hence rollups across data marts are possible and consistent. When a warehouse is made up of data from multiple sources, a conformed dimension is typically (but not always) built from multiple source structures.
The steps in conforming a dimension are:
In a warehouse environment, many dimensions may come from multiple sources. When dimensions are structurally conformed, the warehouse model combines unique attributes from multiple sources to produce a single definition in the warehouse that includes all of the important associated attributes. The MDW contains structurally conformed dimensions with important attributes from all functional areas. Thus, there is a single model for entities such as customer, product, and department, even though multiple source systems such as HCM, CRM, Financials, and EnterpriseOne may define these entities individually.
Cleansing and removing duplicated data:
You can choose to have a data cleansing process as part of the warehouse loading process. For example, the process can take multiple definitions of a value, such as a specific customer, that exist in multiple systems and create a single definition in the MDW. Since the requirements of cleansing and deduping vary from customer to customer, PeopleSoft does not deliver a prepackaged data cleansing solution.
Shared DimensionsDimensions such as Customer, Department, and Item are shared among functional areas or marts within a functional area. To accomplish this sharing, shared dimensions must be consistent in their view of the data. That is, shared dimensions must be identical in structure and content everywhere they are used.
In creating shared dimensions, the application has combined the components from various functional warehouses into one dimension. Although a shared dimension has attributes from various functional warehouses, and any functional warehouse can use this dimension, one warehouse is the owner of each dimension. (For example, in the case of the Customer dimension, CRM is the owner).
Note. For details of shared dimensions, see the PDF file that is published on CD-ROM with your documentation.
See Delivered Warehouse Dimensions.
MDW FactsFact tables contain foreign common key fields to dimensions. Dimension tables have a surrogate ID column that is the primary key of that dimension. A fact table may use these dimension surrogate IDs as foreign keys to the dimension table. In the dimensional model example graphic presented previously, the Sales fact table contains six foreign keys, each one matching a dimension surrounding the fact table.
See MDW Composition.
MDW SetupYou must perform certain setup steps before you can run the ETL process to populate the MDW. This section discusses:
Warehouse Setup Functionality.
Multicurrency Processing.
Tree and Recursive Hierarchy Processing.
Setup Manager.
Gregorian Calendar.
Before you can move data into the MDW, you must perform certain setup steps. For example, multiple source systems can provide information to the Performance Management Warehouse, and each source has its own business units and SetIDs. You must create required business units and assign setIDs that are appropriate for all source systems in the warehouse. When moving control tables into the warehouse, you must convert the source setIDs in the inbound tables into warehouse setIDs that are appropriate for warehouse dimensions (*_D00 in the OWE and D_* in the MDW).
Setup steps include enter parameters in various online pages. Parameters include defining business units and setIDs, among others. ETL jobs use these parameters as input to the jobs.
See Setting Up Warehouse Business Units.
If your company conducts business in more than one currency, then you most likely must convert transactions from one currency to another currency. This is necessary because transactional data can be maintained in any currency in which your company does business. You convert transactions from one currency to another currency using the PeopleSoft Currency Conversion utility, an ETL process that you run after you populate the MDW.
Before you run the Currency Conversion utility, you must provide the utility with various parameters, or rules, which the utility uses to convert your transactional data from one specified currency to another.
See Setting Up and Running Currency Conversion for the Performance Management Warehouse.
Tree and Recursive Hierarchy Processing
PeopleSoft transaction systems store hierarchical structures in trees and recursive hierarchies. For the MDW, to integrate with third-party business intelligence tools, you must use the PeopleSoft Tree and Recursive Hierarchy process to flatten and possibly denormalize these hierarchies.
Before you run the Tree and Recursive Hierarchy process, you must provide the process with certain parameters, which the process uses to flatten and denormalize your hierarchies.
See Processing Trees and Recursive Hierarchies.
PeopleSoft Setup Manager implementation utility provides the step-by-step tasks that you must complete to properly implement a PeopleSoft application. Before you can use Setup Manager, you must:
Install PeopleTools.
Ensure that you have checked EPM install options in the Installation Options table for each product that you plan to install. You can generate implementation projects only for products that you have checked.
Run process scheduler.
To determine the setup tasks required for the mart that you are installing, you must generate an implementation project for that specific mart.
See Enterprise PeopleTools PeopleBook: Setup Manager.
The Calendar dimension includes the Gregorian calendar (the calendar with which we are all familiar) and the business calendar. You do not define business calendars that are imported from source systems and the OWE into the MDW. Gregorian calendar setup is included in the MDW setup.
See Setting Up the Gregorian Calendar for the Performance Management Warehouse.
Moving Data into the MDWYou use ETL to import data into the MDW. You can import data into the MDW by:
Loading data from the OWS to the MDW.
This is the most common path. (You must have previously loaded source data into the OWS).
Importing enriched data from the OWE to the MDW.
This is the path for enriched data that is required for dimensional analysis It is warehouse business unit-based. Reporting for Profitability and Global Consolidations are examples.
Importing data directly from a source system to the MDW.
This data will never reside in the Operational Warehouse. This path applies to large amounts of data, specifically CRM's Online Marketing.
See Loading Data Into EPM Foundation.