
 Understanding Tree and Recursive Hierarchy Processing
Understanding Tree and Recursive Hierarchy Processing
This chapter provides an overview of tree and recursive hierarchy processing and Tree and Recursive Hierarchy process results and discusses how to run the Tree and Recursive Hierarchy process.
Understanding Tree and Recursive Hierarchy Processing
This section discusses:
Trees and recursive hierarchies.
Tree Flattener and Tree Denormalizer.
Tree and recursive hierarchy source tables.
Recursive hierarchy processing.
Denormalized tree result balancing.
Skip levels.
Trees and Recursive Hierarchies
PeopleSoft transaction applications store hierarchical structures in the form of trees and recursive hierarchies. In PeopleSoft applications, a recursive hierarchy is a data hierarchy in which all levels of data are from the same data table and the parent-child relationships between levels are defined in the same source table. That is, recursive hierarchies are generic two-column tables, the columns representing parent and child.
However, in the Multidimensional Warehouse (MDW), PeopleSoft hierarchical structures, such as trees, recursive hierarchies, and Address Book-based hierarchies (for EnterpriseOne) must be in denormalized form. This enables efficient data query, as well as integration with third-party business intelligence tools. PeopleSoft’s tree and recursive hierarchy processing provides the functionality to denormalize trees and recursive hierarchies for multidimensional reporting.
You may need to denormalize a relationship (flattened) table into a hierarchy table to use the hierarchical data in business intelligence reporting. The relationship between a node and its parents and children can eliminate the need to perform complex queries during data retrieval, thus improving performance.
The Tree and Recursive Hierarchy process populates existing relationship and hierarchy tables, which are the source for business intelligence reporting. The extract, transform and load (ETL) process that you use to create input tables for business intelligence reporting combines with the ETL Tree and Recursive Hierarchy process, enabling you to flatten and denormalize your data in a single process. You run the Tree and Recursive Hierarchy process at the same time you that run the ETL process to populate the MDW.
Note. The generic word hierarchy refers to any type of hierarchy: tree, recursive hierarchy, and Address Book hierarchy.
The Tree and Recursive Hierarchy process can not process some invalid trees, specifically:
A tree that refers to a node that does not exist in the node table, as specified in the tree structure definition.
A tree that refers to a leaf that does not exist in the detail table, as specified in the tree structure definition.
See Loading Data into the Multidimensional Warehouse.
See Also
Enterprise PeopleTools PeopleBook: PeopleSoft Tree Manager
Tree Flattener and Tree Denormalizer
The PeopleSoft Tree and Recursive Hierarchy process has two parts: tree flattener and tree denormalizer.
First, the Tree and Recursive Hierarchy process flattens a tree or recursive hierarchy into a relationship table. Next, the process denormalizes the data further into a hierarchy table. Although the processes are sequential, not all tree or recursive hierarchy tables must be denormalized into a hierarchy table. Thus, this step is optional. For example, you may not need to denormalize a hierarchy if you are not using it for business intelligence reporting, but only to facilitate fact data processing, as in aggregating data.
PeopleSoft trees, recursive hierarchies, and Address Book-based recursive hierarchies relate each node in a hierarchy only to its direct parent or child. Data stored in this way makes it difficult to access non-subsequent child notes (the “grandchildren,” or further removed generations) of a hierarchy. The relationship table, which is the result of the flattening part of the Tree and Recursive Hierarchy process, makes all generations related to a specific node easily accessible by associating each node in a hierarchy to any of its descendents, direct or indirect.
The output of the denormalization part of the Tree and Recursive Hierarchy process is a hierarchy table. A hierarchy table format associates the lowest level nodes to all of its parents, direct or indirect, in a row of data. That is, the data in a hierarchy table is denormalized such that a node relationship for a particular path within a tree or recursive hierarchy is represented in one row.
The Tree denormalizer process converts trees into a multicolumn data format so that they can be used by your selected business intelligence reporting tool. The output of the tree flattener portion of the process is the input to the tree denormalizer portion of the process. When you process a dimension, you must run the tree flattener and the tree denormalizer in sequential order. When you process a fact, if the fact uses a tree as its source, usually only the tree flattener is required.
You can control the Tree and Recursive Hierarchy process by whether you specify the hierarchy output table name for each tree or recursive hierarchy. If you do not specify a hierarchy output table name (Hierarchy Record Name), the denormalization process does not run and the tree or recursive hierarchy is not denormalized.
See Creating the Hierarchy Group Definition.
Note. PeopleSoft analytical applications use a different ETL process for flattening hierarchical data. Do not confuse that process with the ETL process for business intelligence reporting described here.
Tree and Recursive Hierarchy Source TablesThe Tree and Recursive Hierarchy process can use as its source:
A tree or recursive hierarchy originating in the source database and mirrored in the Operational Warehouse Staging (OWS).
A tree or recursive hierarchy originating from the EPM database Operational Warehouse (OWE).
An Address Book-based hierarchy originating from an F0150 table (the Address Organization Structure Master), if the source is EnterpriseOne.
Note. The Tree and Recursive Hierarchy process cannot process trees that contain a combination of dynamic details and range details. This combination may yield incorrect reporting results when it is used with business intelligence tools.
Enterprise Tree and Recursive Hierarchy Source Tables
Enterprise recursive hierarchy tables are typically data tables; therefore, bringing them into the EPM OWS is similar to the process of bringing any source data table into the OWS using the source to OWS ETL jobs. Before you run the tree denormalizer part of the Tree and Recursive Hierarchy process, if you are using the source database's trees or recursive hierarchies, you must either first bring your source database tree and recursive hierarchy definition and structure tables into EPM OWS, or you must ensure that your EPM trees and recursive hierarchies exist in the EPM database.
This table lists the Enterprise tree source tables that you bring into the OWS before running the Tree and Recursive Hierarchy process:
|
Source Database Tree Metadata Records |
EPM OWS Tree Metadata Records |
|
PSTREESTRCT |
S_TREESTRCT |
|
PSTREESTRCTLANG |
S_TREESTRCTLANG |
|
PSTREEDEFN |
S_TREEDEFN |
|
PSTREEDEFNLANG |
S_TREEDEFNLANG |
|
PSTREENODE |
S_TREENODE |
|
PSTREELEAF |
S_TREELEAF |
|
TREE_NODE_TBL |
S_TREE_NODE_TBL |
|
TREE_NODE_LANG |
S_TREE_NODE_LNG |
See Loading Data Into EPM Foundation.
EnterpriseOne Recursive Hierarchy Source Tables
There is no tree structure for EnterpriseOne source tables. However, there are two types of recursive hierarchy tables:
Recursive hierarchy information stored within a data table, such as F1640, the Activity Master table.
Bringing these tables into the EPM OWS is similar to the process of bringing any source data table into the OWS.
Recursive hierarchy information as separate from the underlying data table, such as F0150, the Address Organization Structure Master.
Bringing tables into the EPM OWS is part of the MDW Tree and Recursive Hierarchy ETL process.
Denormalized Tree Result BalancingA tree is balanced if all of its branches, or paths, are the same length. For example, if one path of a balanced tree is three levels deep, then all of the paths in the tree must be three levels deep. An unbalanced tree has paths of varying length.
Some business intelligence tools, especially ROLAP tools, require that the denormalized dimension tables in the MDW be balanced to use data effectively. If you use a denormalized table for certain third party business intelligence reporting, you must balance the hierarchy such that no columns contain blanks in the denormalized table. Because not all business intelligence tools require denormalized data to be balanced, the balancing process is optional. Because balancing occurs during denormalization, it has no impact on the tree flattening process.
If you choose to perform balancing, you can select up-balancing or down-balancing. Up-balancing is replicating detail data to a higher level. Down-balancing is propagating the lowest level nodes in a tree down to the node level next to the detail. As a result of balancing an unbalanced tree, the description field for the newly created nodes contains a specific notation. This notation is <dd>~, where <dd> is the two-digit level number, for example “03” for level three, and ~, which is the special character that you select for the Hierarchy Balancing Infix field on the Hierarchy Group Definition page.
Note. The balanced node IDs remain the same as their original value.
The balancing process requires up to two parameters on the Hierarchy Group Definition:
The flag to indicate that up-balancing, down-balancing, or no balancing process is to be performed.
The special character to indicate that a node is introduced as a result of the balancing process. (If no balancing is required, you do not populate this field).
Skip LevelsTrees with strictly enforced levels require that each path of the tree has the same depth. You can skip a level if a portion of the hierarchy does not have nodes at that level. For example, one path in a tree may have levels A, B, C, and D, and another path may have levels A, C, and D (skipping level B).
Similar to tree balancing, skip level handling produces synthetic, or artificial, node entries to fill the gap in a denormalized table. For some business intelligence tools, especially ROLAP tools, you must close the gap produced by a skipped level to use the denormalized table effectively.
Because not all business intelligence tools require a skipped level to be closed, skipped level handling is optional. You use the same flag that indicates up-balancing or down-balancing for tree balancing to indicate processing of skip levels. The special mark for nodes that result from skip level processing is applied to the description field. The special mark is <dds>, where <dd> is the two-digit level number and <s> is the special character that you enter in the Skip Level Infix field on the Hierarchy Group Definition page.
Note. The special mark templates that you use for skip level balancing and for regular balancing can be the same or different than the other. For example, you can use <ddb> to refer to the result of balancing and <dds> to refer to the result of resolving a skip level where dd refers to the level number, such as “03”, b refers to the balancing infix character, such as “~”, and s refers to the skip level infix character, such as “#.”
Understanding Tree and Recursive Hierarchy Process Results
This section discusses tree flattener and tree denormalizer output tables and tree flattener and tree denormalizer results.
Tree Flattener and Tree Denormalizer Output TablesRunning the Tree and Recursive Hierarchy process creates:
A relationship table created by the flattening portion of the Tree and Recursive Hierarchy process.
A hierarchy table — if you run the denormalization portion of the process.
In the hierarchy table:
The Tree and Recursive Hierarchy process denormalizes each node of a winter tree to the detail level.
The Tree and Recursive Hierarchy process denormalizes only the leaves in a summer tree to the detail level.
An unbalanced level, skip level, or both, has a special character infix, which you specified on the Hierarchy Group Definition page, for example ~ , concatenated with the tree node ID in the denormalizer output table TRDN.
The output table structures of the MDW flattened tree or recursive hierarchy relationship data are similar for all relationship tables, except for the keys, which indicate whether the trees are SetID, business unit, or user-defined based.
The resulting MDW relationship table is also effective-dated. When the source is a tree, the effective date of the relationship table is the tree effective date. When the source is a recursive hierarchy, the effective date of the relationship table is the recursive hierarchy process date.
The name of the relationship table has the prefix R_.
Because the relationship table has a description field, the hierarchy processing creates a related language table for the relationship table. This related language table has all of the keys of the base relationship table, plus one additional key, LANGUAGE_CD. (The non-key field that is in the related language table for the relationship table is the description field).
For hierarchy tables, the keys match the keys of the trees or recursive hierarchy, either SetID, business unit, or user-defined key based. The output hierarchical table is also effective-dated. When the source is a tree, the effective date of the hierarchy data is the tree effective date. When the source is a recursive hierarchy, the effective date of the hierarchy data is the recursive hierarchy process date.
Hierarchy tables have a description field for each of the supported levels for denormalization. (PeopleSoft supports 32 levels for a table). Except for the entity ID and description, which are the lowest level, the ID and description are named L<n>_ID and L<n>_DESCR, where n is between 1 and 31, which is one less than the number of supported levels.
The name for a denormalized table has a prefix of H_.
Because a hierarchy table has a description field, the process creates the related language table for the hierarchy table. The related language table for the hierarchy table has all of the keys of the base hierarchy table, plus one additional key called LANGUAGE_CD. (The non-key fields that exist in the related language table of the hierarchy table are the description fields).
You use flattened (relationship) tables and denormalized (hierarchy) tables for business intelligence reporting, and, therefore, the tables have description fields. Thus, both types of tables have related language tables for multi-language reporting. If your company does not require multi-language processing, you do not have to populate the related language tables on the Relationship Record Definition and Hierarchy Record Definition pages. However, you must still define the relationship record name on the Relationship Record Definition page, and if you are running the denormalization part of the process, you must also define the hierarchy record name on the Hierarchy Record Definition page.
The Tree and Recursive Hierarchy process populates related language tables only if you specify a relationship language and outrigger record on the Relationship Record Definition page or a hierarchy language and outrigger record on the Hierarchy Record Definition page.
See Setting Up Multilanguage Processing.
Tree Flattener and Denormalizer ResultsThe output of flattening and denormalizing trees depends on the type of tree: summer, or winter, balanced or unbalanced, skip level, and so on.
This graphic shows an example of a winter tree before processing:
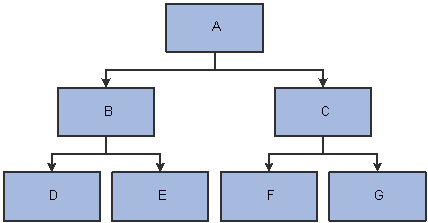
Example of a winter tree before processing
This table shows the winter tree relationship table after tree flattening:
|
Parent Key |
Entity Key |
|
A |
A |
|
A |
B |
|
A |
C |
|
A |
D |
|
A |
E |
|
A |
F |
|
A |
G |
|
B |
B |
|
B |
D |
|
B |
E |
|
C |
C |
|
C |
F |
|
C |
G |
|
D |
D |
|
E |
E |
|
F |
F |
|
G |
G |
This table shows the winter tree hierarchy after tree denormalizing:
|
Entity |
L31 |
... |
L4 |
L3 |
L2 |
L1 |
|
A |
A |
|||||
|
B |
B |
A |
||||
|
C |
C |
A |
||||
|
D |
D |
B |
A |
|||
|
E |
E |
B |
A |
|||
|
F |
F |
C |
A |
|||
|
G |
G |
C |
A |
This graphic shows an example of a summer tree before processing and without any balancing:
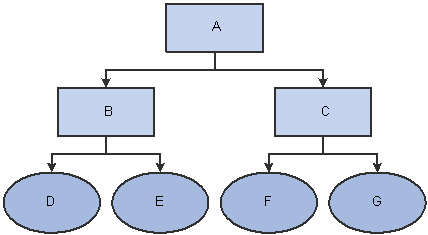
Example of a summer tree before processing
This table shows the summer tree relationship table after tree flattening:
|
Parent Key |
Entity Key |
|
A |
D |
|
A |
E |
|
A |
F |
|
A |
G |
|
B |
D |
|
B |
E |
|
C |
F |
|
C |
G |
This table shows the summer hierarchy after tree denormalizing and without balancing:
|
Entity |
L31 |
... |
L4 |
L3 |
L2 |
L1 |
|
D |
B |
A |
||||
|
E |
B |
A |
||||
|
F |
C |
A |
||||
|
G |
C |
A |
Note. In the previous example, the columns for levels 3 through 31 are not populated because the balancing option is turned off.
If the balancing option were turned on, levels 3 through 31 would also be populated.
If your relationship or hierarchy tables require multi-language support, then you must create the outrigger tables for the
relationship and hierarchy tables.
Running the Tree and Recursive Hierarchy Process
To run the Tree and Recursive Hierarchy process, use the Tree Hierarchy-Relational Table (TH_RELTBL_DEFN) component, Tree Hierarchy-Hierarchy Table (TH_HIERTBL_DEFN) component, and Tree Hierarchy-Hierarchy Group Definition (TH_HIERGRP_DEFN) component.
This section provides an overview of parameters for the Tree and Recursive Hierarchy process and discusses how to:
Define the target and language tables for tree flattening.
Define the target and language tables for tree denormalizing.
Create the hierarchy group definition.
Defining Parameters for the Tree and Recursive Hierarchy ProcessBecause you must first flatten all hierarchies that are processed, you must define the relationship table that is the target for the flattening process. Because the denormalization process is optional, you must define the hierarchy table only if you intend to denormalize the flattened table.
You launch the Tree and Recursive Hierarchy process from the ETL run control page. On this page, you enter the Hierarchy Group ID that you intend to process.
Pages Used to Run the Tree and Recursive Hierarchy Process
|
Page Name |
Object Name |
Navigation |
Usage |
|
TH_RELTBL_DEFN |
EPM Foundation, EPM Setup, Common Definitions, Hierarchy Group Definition, Relationship Table Definition |
Define the target and language tables for tree flattening. |
|
|
TH_HIERTBL_DEFN |
EPM Foundation, EPM Setup, Common Definitions, Hierarchy Group Definition, Hierarchy Table Definition |
Define the target and language tables for tree and hierarchy denormalizing. |
|
|
TH_HIERGRP_DEFN |
EPM Foundation, EPM Setup, Common Definitions, Hierarchy Group Definition, Hierarchy Group Definition |
Enter parameters for the Tree and Recursive Hierarchy process. |
Defining the Target and Language Tables for Tree Flattening
Access the Relationship Record Definition page.
|
Relationship record name |
Displays the target record for the flattening portion of the Tree and Recursive Hierarchy process. |
|
Relationship language record |
Enter the language record for this relationship table. This value is required only if this table is used for multi-language processing. |
|
Relationship outrigger record |
Enter the outrigger record for this relationship table. This value is required only if this table is used for multi-language processing. |
Defining the Target and Language Tables for Tree Denormalizing
Access the Hierarchy Record Definition page.
|
Hierarchy record name |
Displays the target record for the denormalizing portion of the Tree and Recursive Hierarchy processing. |
|
Hierarchy language record |
Enter the language record for this hierarchy table. You must enter this value only if this table is used for multi-language processing. |
|
Hierarchy outrigger record |
Enter the outrigger record for this hierarchy table. You must enter this value only if this table is used for multi-language processing. |
Creating the Hierarchy Group Definition
Access the Hierarchy Group Definition page.
The Hierarchy Group Definition page contains a list of trees, recursive hierarchies, or both, that are related to a particular business process. For example, when you perform a workforce composition analysis, you must analyze data along organization, jobcode, and compensation code hierarchies. In this case, you can define the organization tree, jobcode tree, and compensation tree in one hierarchy group on the Hierarchy Group Definition page. Then, to perform workforce composition analysis, you only need to run tree processing using that Hierarchy Group ID as the parameter. When you run the Tree and Recursive Hierarchy process for that Hierarchy Group ID, the trees and recursive hierarchies that are associated with that ID are processed into either relational or hierarchical tables.
Note. The Hierarchy Group Definition page shown above is an example of this page using certain field values. If your field values differ, the fields that are available may be different. The following table of terms includes a list of all possible fields and the situations under which they display on this page.
|
Hierarchy Group ID |
Displays the identifier for a group of trees, recursive hierarchies, or both, that relate to a specific business process, that you intend to process into relationship or hierarchical tables. You can add a new Hierarchy Group or modify an existing Hierarchy Group for this Hierarchy Group ID. |
|
Hierarchy Balancing Rule |
Enter the balancing rule if the hierarchy is unbalanced. The options are:
|
|
Skip Level Infix |
Enter the special character to indicate skip level nodes that result from the balancing process. You must enter this character only if you have selected Up Balancing or Down Balancing as the Hierarchy Balancing Rule. |
|
Hierarchy Balancing Infix |
Enter the special character to indicate balancing nodes that result from the balancing process. You must enter this character only if you have selected Up Balancing or Down Balancing as the Hierarchy Balancing Rule. |
|
Hierarchy Sequence Number |
Enter the sequence number within the Hierarchy Group ID for this tree or recursive hierarchy. |
|
Hierarchy Source |
Select the source database ID for this hierarchy. The options are: Current EPM Database (for OWE). Noncurrent EPM Database (for OWS). This value refers to the Enterprise or EnterpriseOne source database, as exists on the OWS. |
|
Hierarchy Type |
Select the type of hierarchy. The options are: Tree Recursive Hierarchy Address Book recursive hierarchy |
|
Hierarchy Key Type |
Select the additional key type for this hierarchy. If the type of hierarchy is Tree, the available, the options are:
If the type of hierarchy is Recursive Hierarchy or Address Book recursive hierarchy, only SetID, Business Unit, and None are available. |
|
Relationship record name |
Enter the target table for the flattening part of the process that you identified on the Relationship Record Definition page. |
|
Hierarchy record name |
Enter the target table for the denormalizing part of the process that you identified on the Hierarchy Record Definition page. You must enter this value only if you are denormalizing the hierarchy. |
|
Hierarchy SetID |
Enter the SetID for this hierarchy. This field is available only if the Hierarchy Key Type is SetID. |
|
Hierarchy Business Unit |
Enter the business unit for this hierarchy. This field is available only if the Hierarchy Key Type is Business Unit. |
|
User Defined Value |
Enter the user-defined key value for this hierarchy. This field is available only if the Hierarchy Key Type is User Defined. |
|
Record (Table) Name |
Enter the recursive hierarchy source table name for this hierarchy. This field is available only if the Hierarchy Type is Recursive Hierarchy or Address Book. |
|
Organization Structure Type |
Enter the organization structure type from the Address Book master table. This field is available only if the Hierarchy Type is Address Book. |
|
Tree Name |
Enter the name of the tree for this process. This field is available only if the Hierarchy Type is Tree. |
|
Hierarchy effective date |
Enter the effective date for this hierarchy.
|
|
Operational Key Column |
Enter the column for the operational key for this hierarchy. This field is available only if the Hierarchy Type is Recursive Hierarchy or Address Book. |
|
Parent Key Column |
Enter the column for the parent key for this hierarchy. This field is available only if the Hierarchy Type is Recursive Hierarchy or Address Book. |
|
Description Column |
Enter the column for the description for this hierarchy. This field is available only if the Hierarchy Type is Recursive Hierarchy or Address Book. |
|
Address Book Column |
Enter the column that contains the Address Book. This field is available only if the Hierarchy Type is Recursive Hierarchy or Address Book. |
|
Source System Identification |
Enter the name of the source for this hierarchy. This field is available only if the Hierarchy Source is Nonconcurrent EPM Database. |
Note. You can process multiple hierarchy definitions in one process. Use the + and – boxes on this page to add or subtract hierarchy definitions.