 Using Trees
Using TreesThere are several kinds of metadata that define an Online Analytical Processing (OLAP) cube: dimensional metadata (hierarchy and members), member attribute metadata (consolidation method, sign flip, and label), and cube metadata (dimensions and measures). You use PeopleSoft Tree Manager and PeopleSoft Query to describe all of this metadata to PeopleSoft Cube Manager.
This chapter discusses how to:
Use trees.
Create queries.
See Also
Creating and Running Simple Queries
Using TreesMetadata that exists in PeopleSoft trees can be particularly useful when designing cube dimensions. The main reason to use an existing tree is to leverage the rules that are associated with the outline that the tree represents. Because trees are used to validate information that is stored in the Online Transaction Processing (OLTP) database, all of that tree information is already related to the transactional data. Using effective-dated trees in a cube definition generates the automatic evolution of your data that is used for data analysis.
PeopleSoft Cube Manager leverages the information that is already stored in your PeopleSoft trees as outlines upon which to build each dimension. Using the Rollup Inputs page in PeopleSoft Cube Manager, you map a tree to a dimension so that the rollup of the resulting cube dimension is the same as that of the specified tree.
By default, data is summarized exactly as the tree is defined. Each node and detail value becomes a member of the cube hierarchy for that dimension. The descriptions of the nodes and details become the labels, or aliases, of the members.
Note. What PeopleSoft calls levels are called generations in Hyperion Essbase.
You might want to use existing trees for your dimensions, or you might need to create new trees. If you have an existing tree that is close to what you want the dimension to look like, make a copy of the tree and modify the copy.
If the hierarchy that you want to use is a subset of an existing tree, you do not have to create a whole new tree. PeopleSoft Cube Manager enables you to use a subset of an existing tree by specifying a starting node (Top Node on the Rollup Inputs page) and the number of levels below the top node of the tree to include in the hierarchy. You can use more than one tree belonging to the same business unit to define a single hierarchy.
In addition, if a tree does not provide the structure that you need for a dimension, you can add members, attributes, and levels by using one or more queries to provide the additional metadata.
Because you cannot have duplicate member names in a dimension, unless those members are shared, you cannot duplicate tree node names in your tree metadata. PeopleSoft Cube Manager treats uppercase and lowercase characters as distinct, so the names ABC, Abc,and abc are all considered unique member names. However, Hyperion Essbase offers an option to change all member names to uppercase. If you enable this option, you create problems in PeopleSoft Cube Manager with members that are identical except for their letter casing.
Note. PeopleSoft Cube Manager permits duplicate node names, if you cannot avoid the duplication.
Cognos PowerPlay does not allow duplicate values at any level within the same hierarchy. Cognos PowerPlay requires that the member values are unique in the same hierarchy. Because of this, it drops duplicate values in the same hierarchy while generating the .mdl file. Alternate hierarchies can have detail values (leaves) that appear in the other hierarchies. However, the non-detail values (non-leaf or node) cannot be the same as in any other hierarchy. Duplicate non-detail values cause Cognos PowerPlay to return an error when it is creating the cube.
In Hyperion Essbase, a dimension can have multiple rollups. The resulting total for the first rollup is calculated differently from the resulting totals for subsequent rollups. For example, there is a dimension with two rollups. Two different trees are used for these two rollups. The first tree is set up as A, B, C; while the second tree is A, D, C.
Assume that A, B, C, D have the following fact data values: 2, 5, 10, and 20 (respectively). The total for the first rollup A, B, C is 17 because the total equals to 2 + 5 + 10. The total for the second rollup A, D, C is 10 because each parent gets its total from its children. Because C has the fact value 10, the total for C is 10. Because D is the parent of C, D gets its total from its children. Therefore, D gets 10 from C. A gets its total from its children, which is D. Therefore, A has the total value of 10.
See Also
Creating QueriesThis section provides an overview of query types and discusses:
Dimension queries.
Attribute queries.
Data source queries.
 Understanding Query Types
Understanding Query TypesYou can create several kinds of queries to use with PeopleSoft Cube Manager, all of which you must define as user (ad hoc) queries, as opposed to role queries, or database agent queries.
See Dimension Queries.
See Attribute Queries.
See Data Source Queries.
Because you cannot have duplicate member names in a dimension, unless those members are shared (Hyperion Essbase is the only platform that handles shared members), you cannot have duplicate query column names in your query metadata. PeopleSoft Cube Manager treats uppercase and lowercase characters as distinct, so the names ABC, Abc, and abc are all considered unique member names. However, Hyperion Essbase offers an option to change all member names to uppercase. If you enable this option, you create problems with members that are identical except for their letter casing.
Note. PeopleSoft Cube Manager permits duplicate node names, if you cannot avoid the duplication.
Dimension QueriesDimension queries enable you to define the dimension structure using query results instead of, or in addition to, a tree. However, keep in mind that you are using queries to create a tree-like structure. For narrow query definitions, each dimension query maps child members at a particular level to parent members at the next higher level. For wide query definitions, you only need one query to build the dimension. Optionally, these queries might contain extra members or level attributes, as well as the relationship information.
You can convey hierarchical information in one of two ways: by parent/child relationship (a narrow query) or by level specification (a wide query). This section discusses:
Narrow query definition.
Wide query definition.
When you use multiple queries to define dimensional structure, the first query that you specify defines the first two levels of the dimension. To add lower levels, you must write one additional query for each additional level.
Suppose that you want to build a department dimension that contains the following departments within an organization:

Example of departments within an organization
The levels of the organization might be described as follows:
|
Level 1 (top of dimension) |
Level 2 |
Level 3 |
|
ALL DEPARTMENTS |
DEVELOPMENT |
100 |
|
|
|
200 |
|
|
SALES |
300 |
|
|
|
400 |
|
|
|
500 |
To create the dimension, you must write two queries to provide the preceding information: one to define the child members at level 2 and one to define the child members at level 3.
Query 1:
|
Parent |
Member (Child) |
|
ALL DEPARTMENTS |
DEVELOPMENT |
|
ALL DEPARTMENTS |
SALES |
Note. During the build, PeopleSoft Cube Manager knows that child members with an unspecified parent become level 2 members, directly under the top of the dimension. You can create an empty column in a query by adding a blank ("") expression. Be sure to enter some meaningful text for the heading text and unique field name (such as "Top of Dimension") so that you can easily identify the blank column when mapping query columns to dimension levels.
Query 2 must return one column for the second-level members (DEVELOPMENT and SALES) and one column for the third-level members (100, 200, 300, 400, and 500).
The query results look like this:
|
Parent |
Member (Child) |
|
DEVELOPMENT |
100 |
|
DEVELOPMENT |
200 |
|
SALES |
300 |
|
SALES |
400 |
|
SALES |
500 |
To add additional levels, write one query for each additional level. Building on the previous example, assume that you want to create an employee dimension in addition to a department dimension. In this case, include a fourth level showing the employees in each department:
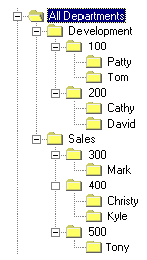
Example of employees within an organization
Now you might describe the levels of the organization as follows:
|
Level 1 |
Level 2 |
Level 3 |
Level 4 |
|
ALL DEPARTMENTS |
DEVELOPMENT |
100 |
Patty |
|
|
|
|
Tom |
|
|
|
200 |
Cathy |
|
|
|
|
David |
|
|
SALES |
300 |
Mark |
|
|
|
400 |
Christy |
|
|
|
|
Kyle |
|
|
|
500 |
Tony |
In addition to the two queries that you create, you must create a third query with the following results in order to add the fourth level to the dimension:
|
Parent |
Child |
|
100 |
Patty |
|
100 |
Tom |
|
200 |
Cathy |
|
200 |
David |
|
300 |
Mark |
|
400 |
Christy |
|
400 |
Kyle |
|
500 |
Tony |
The following diagram illustrates how you supply three queries to create a dimension with four levels:
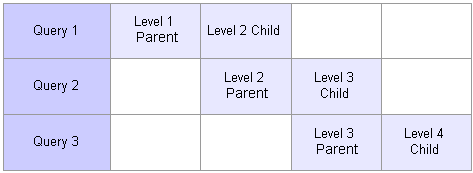
Four-level dimension created using three queries
Your dimension queries should always produce at least two columns in the result set: one for the parent and one for the child (or member). Except for the top-level query, a parent column for a given level must always correspond to the child column of the previous level.
Optionally, you can include attributes in the query. All attributes that you specify in a narrow query are associated with the field that is specified as the member. You must add attributes for the topmost member by using an attribute query.
When defining your dimension with a wide query, follow the same logic that is used with narrow queries.
Using the previous example for narrow queries, the following table illustrates the dimension that you want to build with a wide query:
|
Level 1 |
Level 2 |
Level 3 |
Level 4 |
|
ALL DEPARTMENTS |
DEVELOPMENT |
100 |
Patty |
|
|
|
|
Tom |
|
|
|
200 |
Cathy |
|
|
|
|
David |
|
|
SALES |
300 |
Mark |
|
|
|
400 |
Christy |
|
|
|
|
Kyle |
|
|
|
500 |
Tony |
Instead of writing multiple queries to build this dimension, write one that contains only this information. The query result set might look like the following:
|
Level 1 |
Level 2 |
Level 3 |
Level 4 |
|
ALL DEPARTMENTS |
DEVELOPMENT |
100 |
Patty |
|
ALL DEPARTMENTS |
DEVELOPMENT |
100 |
Tom |
|
ALL DEPARTMENTS |
DEVELOPMENT |
200 |
Cathy |
|
ALL DEPARTMENTS |
DEVELOPMENT |
200 |
David |
|
ALL DEPARTMENTS |
SALES |
300 |
Mark |
|
ALL DEPARTMENTS |
SALES |
400 |
Christy |
|
ALL DEPARTMENTS |
SALES |
400 |
Kyle |
|
ALL DEPARTMENTS |
SALES |
500 |
Tony |
As with narrow queries, the query can return attributes that you can associate with members. However, in the case of wide queries, you can assign the attributes to any member.
Attribute QueriesYou can use attribute queries to set optional attributes on the members within a dimension. Set attributes on either node members or detail members of a dimension.
An attribute query should return at least two result columns: one that identifies the members whose attributes you want to define and one for each type of attribute to be set.
|
Member |
Attribute 1 |
Attribute 2 (Optional) |
Attribute 3 (Optional) |
|
1000 |
XXX |
XXX |
|
|
1100 |
XXX |
XXX |
XXX |
|
1200 |
XXX |
|
XXX |
|
1300 |
XXX |
XXX |
|
Most attribute types are platform-specific: they are used by one of the target platforms, but not all. Each attribute type uses its own set of conditions to determine whether to apply the attribute. In some cases, for the attribute to be applied, the attribute column must contain a specific value. In other cases, the attribute column must simply not be blank. An attribute query can return a subset of the members, in which case the specified attributes are set only on those members returned.
If an attribute query is on a table that uses a setID, you must select only the setID in which you’re interested. Thus, only one member ID field exists to tie the query results to the dimension.
Note. In the preceding example, one query sets three attributes. You can also create three separate queries in which you return the member and one attribute.
You can define numerous types of attributes by using queries and PeopleSoft Cube Manager. We discuss the following valid attribute types:
Refers to the reversal of + and − signs for the member, which is sometimes necessary for accounting purposes. Valid values are blank (do not flip the sign) or non-blank (flip the sign). In a star schema, an attribute column is populated with a value of – 1 when a member has a sign to flip. In Cognos PowerPlay and Hyperion Essbase, the data that is populated in a flip-signed cell has the opposite sign of the source query.
Provides a description for a member. In a Hyperion Essbase database, this equates to the default alias. In a Cognos PowerPlay PowerCube, it equates to the label. For star schemas, the label is a description of the member.
Applies to Hyperion Essbase only. Hyperion Essbase enables you to specify user-defined attributes for members. You can then use calculation (calc) scripts to search for and manipulate members that have particular user-defined attribute values.
PeopleSoft Cube Manager supports user-defined attributes. To design your own user-defined attributes, select PeopleTools, Cube Manager, Attribute Definitions.
Hyperion Essbase has the following valid attribute types:
Applies to account-type dimensions. This attribute specifies a member that requires currency conversion to a specific category type. In the attribute query field, supply the type of conversion that is required (a value, normally in dollars).
Applies to account dimensions. This attribute equates to the Currency Conversion buttons on the Account tab of the Attributes dialog box for an account dimension in the Hyperion Essbase Application Manager.
If the Currency Category attribute is set to a non-blank value on a member, that non-blank value is automatically applied to the Currency Conversion Type attribute. If the Currency Category attribute is set to blank, the Currency Conversion Type attribute is automatically set to inherit-use ancestor. If the Currency Category attribute is not applied at all, the Currency Conversion Type attribute is automatically applied with a value of no conversion ("").
If you set this attribute manually, valid values are blank (no conversion) or non-blank. If the query returns a non-blank value, that value is used as the Currency Category.
Applies to country dimensions. The value of this attribute defines what type of currency the country or market region uses. This value identifies the type of currency in a currency cube.
Tells Hyperion Essbase what type of storage to allocate for the member. Valid values are 0 or blank (store data), 1 (never share), 2 (label only), 3 (shared member), 4 (dynamic calculation and store), and 5 (dynamic calculation, no store). PeopleSoft Cube Manager sets the default value as store data for all members in the first rollup and the non-detail nodes of all other rollups. Detail nodes in secondary rollups are set to shared members.
Expense item applies to account dimensions only. Hyperion Essbase has certain built-in formulas that can take advantage of the knowledge that an item is an expense. To pass this knowledge on to Hyperion Essbase, you should use this attribute. Valid values are Blank (set) and non-Blank (do not set).
Affects how the parent time value is calculated. Valid values are 0, 1, 2, and 3; which correspond to none, first, last, and average, respectively.
Referred to as the consolidation attribute. This attribute enables you to define the mathematical operator used for rolling up members. Most often, you expect that data is added (using the + operator) when rolled up. However, you might occasionally need to specify other operators, such as those listed in the following table:
|
Valid Value |
Action |
|
+ (plus sign) |
Add (default) |
|
– (minus sign) |
Subtract |
|
* (asterisk) |
Multiply |
|
/ (forward slash) |
Divide |
|
[Blank] |
Do not consolidate. |
|
~ (tilde) |
Do not consolidate. |
|
% (percent sign) |
Divide the total of previous member calculations by this member and multiply by 100. |
Cognos PowerPlay has the following valid attribute types:
Equates to any valid description in Cognos PowerPlay, meaning that it can contain unlimited text.
Equates to the short name. Valid values are any valid Cognos PowerPlay short name.
See Also
Hyperion Essbase and Cognos PowerPlay Services documentation
Data Source QueriesData source queries define the data that you bring into the cube. Writing a data source query is straightforward; the query must return one column for each dimension and one column for each measure. Assume that you want to build a data source query for a cube containing amounts that are dimensioned by account, department, and period. The output of your query has four columns:
|
Account (Dimension) |
Dept (Dimension) |
Period (Dimension) |
Amount (Measure) |
|
XXX XXX |
XXX XXX |
XXX XXX |
XXX XXX |
You can use several queries as the data source for a single cube, thus defining multiple measures. Every data source query that is used must include an output column for every dimension that is used and for at least one measure. However, you are not required to provide an output column for every measure in every data source query.
The following example shows how you can use two separate queries as a data source for a cube. Note that both queries return columns for every dimension, as required, and that they differ only in which measure they include.
Results of Query 1:
|
Account (Dimension) |
Dept (Dimension) |
Period (Dimension) |
Budget Amount (Measure 1) |
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
4000 6000 |
Results of Query 2:
|
Account (Dimension) |
Dept (Dimension) |
Period (Dimension) |
Actual Amount (Measure 2) |
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
3000 5000 |
Resulting cube using query 1 and query 2 as data sources:
|
Account (Dimension) |
Dept (Dimension) |
Period (Dimension) |
Budget Amount |
Actualize Amount |
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
4000 6000 |
3000 5000 |