Running the Content Categorization Process
This section discusses how to:
Identify data source folders and files.
Define a content source by creating a search definition, search category, and deploying the search definition and search category.
Associate a content source with a folder.
Run the content categorization process.
|
Page Name |
Definition Name |
Navigation |
Usage |
|---|---|---|---|
|
Categorized Content Source |
EPPCM_CATG_SOURCE |
Click a folder title link on the Browse Categorized Content page to navigate through the folder levels. Click a folder Properties link or click the Add Folder button at the appropriate folder level on the Browse Categorized Content page. Select the Categorized Content Source tab. |
Associate an already defined content data source with the selected folder in categorized content. |
|
Categorize Crawled Content |
EPPCM_CATG_RUN |
|
To read index and build categorized content. |
|
Process Scheduler Request |
PRCSRQSTDLG |
Click Run. |
To run the content categorization Application Engine process. |
PeopleSoft Interaction Hub is integrated with Oracle search engine, so search definitions are used to specify exactly what is crawled.
Oracle search engine can crawl files or directories located on the server where search engine is installed or network file paths accessible by the server. Also, search engine can crawl a web server.
Before running the Application Engine process, you should become familiar with the folder hierarchy and documents available on the source system. You will want to examine the source system to determine:
The root folder in which to begin the crawl.
The depth to which you want the crawler to crawl.
The type of documents you want to retrieve.
See the product documentation for PeopleTools: Search Technology, “Creating File Source Search Definitions,” Specifying File Source General Settings.
See the product documentation for PeopleTools: Search Technology, “Creating Web Source Search Definitions,” Specifying Web Source General Settings.
The Oracle default document types for crawling are:
PDF
HTML
TXT (plain text)
Microsoft Word
Microsoft Excel
Microsoft PowerPoint
See the product documentation for PeopleTools: Search Technology, “Creating File Source Search Definitions,” Specifying Document Types.
See the product documentation for PeopleTools: Search Technology, “Creating Web Source Search Definitions,” Specifying Document Types.
As part of defining a content source, you must complete the following tasks:
Create a search definition for each file source or web source to be crawled.
The search definition determines among other things:
The starting URL (or multiple URLs).
The maximum file size (which could exclude some files from the results).
The valid file types (which could exclude other files from the results if not set appropriately).
Create a corresponding search category for each search definition.
Deploy the newly created search definition. The corresponding search category is automatically deployed when you deploy the search definition.
Build the search index.
Create a folder and assign it to a crawl source.
Run the Application Engine (EPPCM_CATG) process to read the index and build categorized content.
Use the Categorized Content Source page (EPPCM_CATG_SOURCE) to associate an already defined content data source with the selected folder in the content management system.
Navigation:
Click a folder title link on the Browse Categorized Content page to navigate through the folder levels.
Click a folder Properties link or click the Add Folder button at the appropriate folder level on the Browse Categorized Content page.
Select the Categorized Content Source tab.
This example illustrates the fields and controls on the Categorized Content Source page. You can find definitions for the fields and controls later on this page.
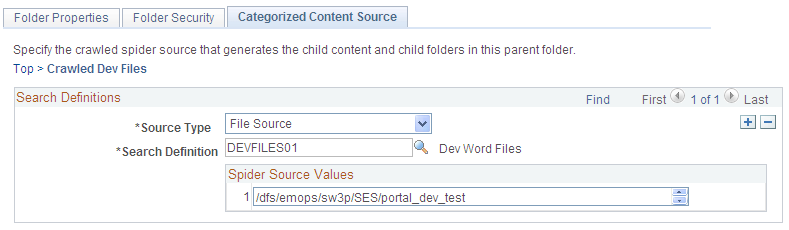
This page is used to specify the crawled source that generates the child content and child folders in this parent folder.
Note: You must set up your content sources using custom search definitions and categories before you enter information on this page.
Field or Control |
Description |
|---|---|
Source Type |
Specify the same source type that was specified when creating the custom search definition. Available options are:
|
Search Definition |
Select a search definition from a list of available names. The search definition is restricted to those that you created for crawling content with the selected source type. |
Spider Source Values |
When you select a value for the search definition using the lookup prompt, the system automatically inserts the correctly formatted string into the Spider Source Values field based on the value defined for the Starting URL field on the Search Definition page. |
Use the Categorize Crawled Content page (EPPCM_CATG_RUN) to read index and build categorized content.
Navigation:
The Categorize Crawled Content page is used to run the content categorization Application Engine (EPPCM_CATG) process.
This example illustrates the fields and controls on the Categorize Crawled Content page. You can find definitions for the fields and controls later on this page.
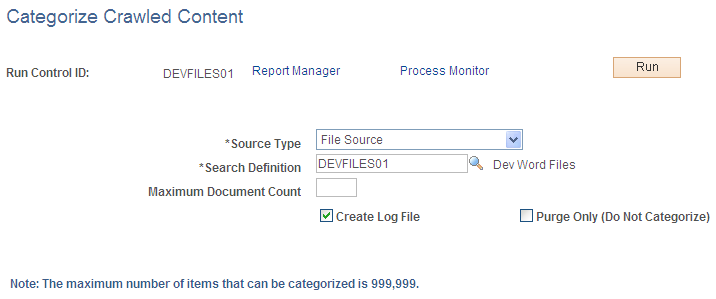
The content categorization Application Engine process reads the search index through PeopleSoft Search Framework (PTSF) APIs and extracts details about the content such as title, description which is used to create the content. The content created is of type U with a URL value pointing to either a web page or the location on the server for a file.
When the Application Engine process is re-run, new content is added to the content management system. Existing content is ignored. Due to the latter scenario, revised content will not be updated and would have to be manually removed from the Published status or deleted from the PeopleSoft Interaction Hub system prior to re-running the Application Engine process. Also, in cases where a file is renamed, the content title in the content management system will not be synchronised and it would be better to delete from the folder and re-run.
Note: The Application Engine process does not have the ability to process children folders, so only documents from the specified root folder are crawled.
Note: The search engine crawl is for non-secured content. Folder level security does not apply to the crawled content because the content is external to the PeopleSoft Interaction Hub database. If you require security at the folder level, you need to use Managed Content instead, and attach each file in managed content using the standard Managed Content type of file attachment.
Field or Control |
Description |
|---|---|
Source Type |
Specify the same source type that was specified when creating the search definition for crawling. Available options are:
|
Search Definition |
Select a search definition from a list of available names. The search definition is restricted to those that you created for crawling content with the selected source type. |
Maximum Document Count |
Enter the maximum number of documents and directories that the job should categorize before terminating. Note: The content categorization process can categorize a maximum of 999,999 items. |
Create Log File |
Select to create a log file. The log file appears in the files subdirectory of process scheduler: PS_CFG_HOME/appserv/prcs/DOMAIN_NAME/files. This file provides details about the processed URLs and their associated folder path directories. |
Purge Only (Do Not Categorize) |
Select to delete the contents of the folder. |
To read index and create links to the crawled content:
Select .
Enter details in the fields.
Click Run.
This example illustrates the Process Scheduler Request page.
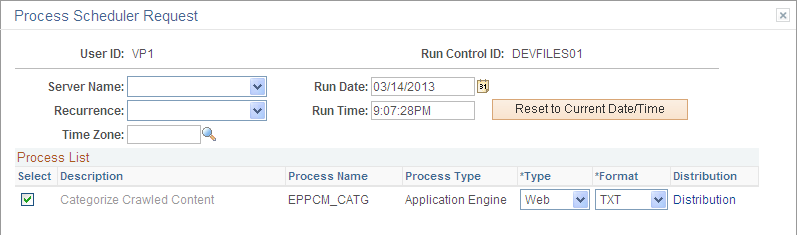
After you have run the process using the Process Scheduler Request page, use the Process Monitor page to monitor the status of your process request and verify that the process has completed successfully.
On successful completion of the process, the folder associated with the content source will be populated with content in Published status.