 Understanding Payment Predictor Processing
Understanding Payment Predictor ProcessingThis chapter provides an overview of Payment Predictor processing and discusses how to:
Define algorithm groups.
Define payment predictor methods.
Set up parallel processing.
Select payments for Payment Predictor processing.
Review payment predictor temporary tables and sections.
Note. This chapter is required. You must complete the tasks discussed in this chapter to implement Payment Predictor processing.
Understanding Payment Predictor ProcessingThe Payment Predictor Application Engine process (ARPREDCT) is the automatic cash application process in Receivables. It provides an alternative to applying payments using an express deposit or payment worksheet. Think of Payment Predictor as an automated version of the payment worksheet, which is used to match payments manually to open items or to create adjustments or write-offs for overpayments and underpayments. The items, which have a payment method of cash, check, credit card, electronic file transfer, or giro - EFT, qualify for Payment Predictor processing. The ones with direct debit and draft payment methods are processed by other processes.
This section discusses:
The Payment Predictor process flow.
Algorithms and methods.
Payment Predictor and multicurrency processing.
Item-level adjustments and reference values.
Payment Predictor multiprocess job.
 The Payment Predictor Process Flow
The Payment Predictor Process FlowPayment Predictor processes payments in stages. Before you run the Payment Predictor process, you must establish a hierarchy for processing business units, customers, deposits, and payments. You must also decide which customers or payments should be excluded from Payment Predictor.
The source of payments does not matter when you use Payment Predictor. Payments can be online payments—entered in a regular or express deposit—or they can enter the system through an electronic interface, such as electronic data interchange (EDI), bank statement reconciliation, a lockbox interface, or the cash drawer receipts interface (CDR_LOADPMT).
Each payment must have a Magnetic Ink Character Recognition (MICR ID), customer ID, or some other type of reference information. The system uses the reference information to match payments to customers.
Payment Predictor first looks for the MICR ID. If it finds a valid MICR ID, it moves on to the next stage. If it does not find a valid MICR ID, it then looks for a customer ID with a business unit. If it does not find a valid customer ID with a business unit, then it looks for a customer ID without a business unit and uses the deposit business unit to determine which setID should identify the customer and the remit from customer.
After Payment Predictor finds and validates the reference information, it stores the results in temporary tables. The temporary tables are used to identify which payment processing method the system uses.
When you set up Payment Predictor, you create a payment predictor method that includes a detailed set of instructions for applying payments. The method also includes instructions for handling payments that cannot be applied, such as placing the payment on the customer’s account, generating a payment worksheet, so the payment can be manually applied, or releasing the payment.
After Payment Predictor has completed every step in the method, it moves the payment information from the temporary tables to the application tables.
Note. If the only reference information is the deposit business unit, you can direct Payment Predictor to apply the payment to a control customer. To do so, create a payment predictor method that contains a step without an identified customer identity and without an instruction to generate an item for a control customer. Assign this method to the deposit business unit.
This diagram shows the process flow of Payment Predictor.
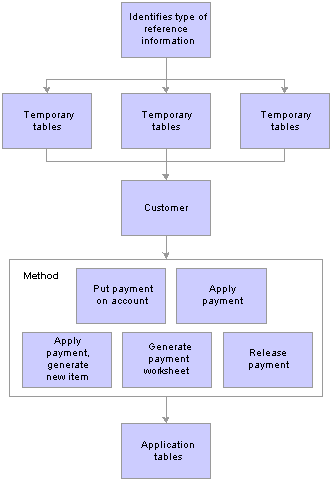
Payment Predictor process flow
Algorithms and MethodsBefore you use Payment Predictor, you must establish exactly what you want it to do. How will you handle overpayments and underpayments? Should complex payments be reviewed before posting? You use algorithms and methods to tell Payment Predictor what kind of payment situations to expect and how to handle each one.
Algorithms are SQL statements that match payments with open items according to the criteria that you specify. Algorithm groups are collections of related algorithms. For example, the algorithm group PASTDUE includes two algorithms: PASTGR for all past due items without a discount and PASTNET for past due items with a discount.
Methods are a series of steps that are performed conditionally based on remittance information. Methods reference one or more algorithm groups.
Payment Predictor’s algorithms use SQL to define how to match payments with open items. The program’s flexibility means that the required setup generally needs the attention of the technical members of your project team who are fluent in SQL, especially for changes to algorithms. For method setup, the more technical members of the project team require input from the team members familiar with your customers’ remittance patterns and exception processing procedures.
Payment Predictor and Multicurrency ProcessingPayment Predictor applies payments even if the currency for the item and the currency for the payment are different. When more than one currency is involved in a payment, Payment Predictor looks at the following:
The payment currency (PAYMENT.PAYMENT_CURRENCY).
The base currency of the deposit business unit (PAYMENT.CURRENCY_CD).
The item currency (ITEM.BAL_CURRENCY).
The base currency of the item business unit (ITEM.CURRENCY_CD).
If the currencies are different, the process places the rows that have different currencies in the Payment Predictor Multicurrency Conversion table (PS_PP_MULTC_TAO). It converts the item amount to the currency for the payment using the exchange rate on the payment date to do the conversion.
Payment balancing is performed in the payment currency. The PAY_AMT field in the PS_PP_ITEM_TAO table contains the item amount in the payment currency. When a step in a payment predictor method generates an item to balance a payment, the Payment Predictor process uses exchange rate information for the payment and creates the item in the payment currency.
The system calculates a gain or loss if there is a difference between the item amount in the base currency for the item's business unit on the item's accounting and payment dates.
If there is a gain or loss amount for a discount, the amount is included in the item's realized gain and loss calculation.
Payment-Level Adjustments
When you use the #REFS algorithm group, and there is one payment in a deposit that pays for multiple items, Payment Predictor creates one adjustment entry at the payment level instead of the item level. For example, if a payment pays for two items, Payment Predictor looks at the sum of both items and the payment amount. It uses this information to determine whether an overpayment or underpayment condition exists and to create one adjustment entry. The adjustment entry is either an on-account or write-off item.
Detail reference information always includes the amount of the payment that Payment Predictor applies to an item. If the amount of the payment does not match the amount of the item, Payment Predictor handles it as follows:
Closes the item as paid in full.
Calculates any realized gain or loss based on the entire amount, if needed.
Creates a new item based on the action to be taken defined on the payment predictor method with the exception of Release the Payment. For example, it could be to put it on account, write it off, make an adjustment or make a deduction with an option to create worksheet for review before posting. The action choice made in the payment predictor method for each condition should be tailored to your specific business requirements.
For example, a detail payment method could designate the following actions dealing with an unmatched payment:
When the overpayment exceeds 100.00 EUR or 25%, it releases payment for next matching.
No new item is created on this condition.
When the underpayment exceeds 5.00 EUR, it creates a deduction item with the unmatched amount as its balance amount.
When the underpayment is less than 5.00 EUR, it creates an item with the amount and write it off.
The new item has the original item ID in the document field as a reference. The process actually creates two items in this case. For underpayments, it creates a WS-07 item to adjust the underpayment and then a WS-11 item (write-off an underpayment).
See Also
Understanding Realized Gain and Loss Processing
Item-Level Adjustments and Reference ValuesIf Payment Predictor creates new on-account, underpayment, overpayment, prepayment, or deduction items when it applies a partial payment, it assigns the reference information provided with the payment to the new items. The process uses the reference qualifier code in the Payment ID Item table (PS_PAYMENT_ID_ITEM) to determine what reference field to populate for the new item. If a payment has multiple references, the process retains all the reference values unless there are multiple references for the same reference qualifier code.
This table provides an example of how the process assigns reference values if there are multiple references.
|
Reference Qualifier Code |
Reference Value |
Action |
|
I (item) |
Item100 |
Does not assign reference value to new item. |
|
I (item) |
Item200 |
Does not assign reference value to new item. |
|
O (order) |
Order100 |
Assigns reference value to new item. |
|
P (purchase order number) |
PO100 |
Assigns reference value to new item. |
The process populates reference values in these fields:
Document
Item ID
Bill of Lading
Letter of Credit
Order Number
PO Ref (purchase order reference)
SubCustomer1
SubCustomer2
If the reference value has the I (item) reference qualifier code and the value is the same as the item ID for the new item, the process places the reference value in the Document field.
This enables you to match new credits and debits with the items that Payment Predictor creates using the Automatic Maintenance process. To match the items, you should build automatic maintenance methods that match items by the appropriate reference fields and item amounts. This is very useful if you use the Cash Drawer Receipts feature to enter payments and deposits for counter sales.
See Also
Setting Up Automatic Maintenance Methods
Payment Predictor Multiprocess JobThe Payment Predictor multiprocess job (ARPREDCT) is a shell process that runs multiple subprocesses that process different sets of data concurrently. The multiprocess job contains two subprocesses that run sequentially. The second subprocess runs multiple child processes in parallel when you set up parallel processing for the Payment Predictor process.
The AR_PREDICT1 Application Engine process gathers the data for the process run, determines how many rows each parallel process should process, and starts each parallel process.
The Payment Predictor multiprocess job (AR_PP) starts after AR_PREDICT1 and calls each of the child processes that you define for it, such as AR_PP1 or AR_PP2. The child processes are multiprocess jobs and run in parallel.
Each child process, such as AR_PP1, calls the AR_PREDICT2 Application Engine process, which does the actual payment application. AR_PREDICT2 matches the payments, updates the application tables, and releases the process instances on tables before ending the process. Each child process has its own process instance number and set of temporary tables and matches payments independently from the other child processes.
See Also
Setting Up Parallel Processing
Defining Algorithm GroupsThis section provides an overview of algorithm groups, Payment Predictor modes, sample algorithm groups, and discusses how to:
View algorithm groups.
Deactivate an algorithm in an algorithm group.
Add an algorithm group.
Use #DETAIL and #DTL_TLR for partial payments and deductions.
Use the #OVERDUE algorithm group.
Review Payment Predictor and special conditions.
Understanding Algorithm GroupsBefore you can use Payment Predictor to apply payments automatically, you must select and refine the algorithms that determine how Payment Predictor handles specific payment situations.
Algorithm groups are a collection of related algorithms. An algorithm group represents a section in the Payment Predictor process and each algorithm in the group represents a step in the section. Each algorithm has at least three statements:
A statement that names the algorithm within the group.
An insert statement that populates the PS_PP_MATCH_TAO temporary table.
This step is usually named for the algorithm within the group, but it can be named anything.
A statement that performs the post-match processing.
Receivables has sample algorithm groups that you can use to set up Payment Predictor. You can use an algorithm group as delivered. You can deactivate the algorithms in the group that you do not want to use, copy the same algorithm group to another method and then deactivate different algorithms. You can create new algorithm groups as needed by copying algorithms from other algorithm groups and then modifying the algorithms to suit your particular needs.
Understanding Payment Predictor ModesAlgorithm groups have instructions for processing payments. The instructions are based on the type of reference information that was used to match payments to customers. This table lists the type of reference information:
|
Type |
Description |
|
Customer Reference |
Information such as the MICR ID or customer ID that is supplied with a payment. If a customer reference is not found, Payment Predictor uses item summary reference information or detail reference information to identify the customer. |
|
Item summary reference information |
Reference information that does not include the amount, for example, an item ID and reference qualifier code of I on payment entry. |
|
Item detail reference information |
Reference information that includes the amount, for example, item ID and item amount on payment entry. |
The following table describes payment predictor modes:
Understanding Sample Algorithm GroupsThe following table lists the sample algorithm groups that come with Receivables. As you review the samples, consider the automatic cash application capabilities of your current system and your customers' remittance patterns.
|
Algorithm Group (SECTION) |
Selects These Open Items |
Use For |
Algorithms in Group (STEPS) |
|
Selects all open items for identified customers, only if the payment amount exactly matches the open items total. |
Payments without item references only and customer identified. |
BALGR Selects all open items. BALNET Selects all open items minus earned discounts. |
|
|
Selects all open items for identified customers only if the payment amount matches an item amount, an item amount with discount, or the total amount of any two items. The algorithm selects an item only if there is only one item that matches the payment amount or if there are only two items that match the payment amount. For example, if the payment amount is 200.00 EUR and there is one item for 200.00 EUR, it selects the item. However, if the payment amount is 200.00 and there are two items each for 200.00 EUR, it does not select any items. |
Payments without item references only and customer identified. |
DEBITGR Selects a single unique open item. DEBITNT Selects a single unique open item minus earned discount. ANY2GR Selects any two unique open item balances combined. |
|
|
Selects items with oldest due dates first until the remaining payment amount is less than the next item. |
Payments without item references only and customer identified. |
OLDEST Selects open items in oldest first order by due date. Creates a partial payment for the next item. |
|
|
Adds all items with credit balances to the payment amount. Then selects items with debit balances in oldest due dates order until the remaining payment amount is less than the next item. |
Payments without item references only and customer identified. |
CREDITS First adds all credits to the payment amount. Then selects open items in oldest first order by due date. Creates a partial payment for the next item. |
|
|
Selects all overdue items for payment matching using the sequence of the overdue charges entry reasons. |
Payments without item references only and customer identified. |
OVERDUE Selects the items to apply to the payment. First uses the sequence of overdue entry reasons. Then selects open items in oldest first order by due date. Creates a partial payment for the next item. |
|
|
Selects all past due items for the customers identified only if the payment amount exactly matches the total of the past due items. |
Payments without item references only and customer identified. |
PASTGR Selects all past due open items. PASTNET Selects all past due open items minus earned discounts. |
|
|
Selects only open items that exactly match the references supplied with a payment. |
Payments with item summary references only and customer identified does not matter. |
ITEMREF Selects all open items identified by the references regardless of customer identification. Enables you to add a unique debit or credit item for an underpayment or overpayment that completes the application. |
|
|
Selects only open items that exactly match the references supplied with a payment. |
Payments with item summary references only and customer identified. |
ONECUST Selects all open items identified by the references limited to the customer whose MICR ID or customer ID is supplied with the payment. Enables you to add a unique debit or credit item that completes the application. |
|
|
Uses reference information that does not exactly match to select items. |
Payments with item summary references only and customer identified does not matter. |
Receivables includes these algorithms as samples of possible ways for dealing with bad references. They are platform-specific and you can take advantage of any functions your database allows. FIRST8 Selects all open items identified by the first eight characters of the references. MIDDLE7 Selects all open items identified by the seven characters after the first four characters in the references. |
|
|
Selects only open items that exactly match the references supplied with a payment. |
Payments with item detail references only and customer identified does not matter. Created adjustments only adjust remaining overpayment or underpayment. |
DETAIL Selects all open items identified by matched references. Also accepts WS-08 deduction references. Payments with detail references should balance, but if not, the #DETAIL algorithm creates an Adjust Remaining Underpayment item for underpayments or an Adjust Remaining Overpayment item for overpayments. |
|
|
Selects only open items that exactly match the references supplied with a payment. |
Payments with item detail references only and customer identified does not matter. |
DTL_TLR Selects all open items identified by matched references. Closes items that match the payment amount. If there is an underpayment that exceeds the tolerances, it looks at the bill to customer to see whether partial payments are allowed. If allowed, it creates a partial payment on the item. The actions taken are based on the selections on the Receivables Options - Predictor Detail Options page. |
|
|
Selects items from the most recent customer statement. |
Payments without item detail references and customer identified. |
STMTALL Selects items from the most recent statement. The payment amount must exactly match the total amount of the items on the statement. |
Viewing Algorithm GroupsThis section explains how to view the contents of an algorithm group.
To view an algorithm group:
Open the AR_PREDICT2 Application Engine program in Application Designer.
Locate the name of the algorithm group in the sections.
Algorithm groups have names that start with # and appear first in the list.
To view details about the algorithms (steps), expand the algorithm group.
Some algorithm groups, such as #BALANCE or #REF, may have steps in a repeating pattern. More details on this pattern are in the example that follows.
To view the SQL statement, double-click the SQL folder for the algorithm.
To understand how a customer-based algorithm group works, examine #BALANCE. This algorithm group compares the amount of the payment to the total of all items for the customer. When you scroll through the steps, you might notice that the steps have a pattern: ALGO_1, BALGR, ALGO_X1, then ALGO_2, BALNET, ALGO_X2.
Payment Predictor evaluates overpayments and underpayments based on the information in the PS_PP_MATCH_TAO. As long as an item has not been selected by another payment, it either fully applies a payment (if it matches the balance of all open items) or it does not apply it at all. An overpayment or underpayment condition cannot exist.
There is one case, however, when an overpayment condition can exist. Payment Predictor processes two payments for the same customer together, and the first payment pays one item while the second payment pays the entire customer balance including that same item. This situation might occur if the customer forgets that the first payment has already been made when they create the second payment. In this case, Payment Predictor determines that the sum of the open items matches the amount of the payment. It inserts only rows for items not already selected by another payment into the PS_MATCH_TAO temporary table. In this limited case, Payment Predictor detects and evaluates an overpayment condition.
If it makes sense in your business environment to apply a tolerance to the evaluation of a balance, modify the algorithm to include a tolerance calculation. This directs Payment Predictor to insert into PS_PP_MATCH_TAO item rows for which the total nearly, but not exactly, matches the amount of the payment. This in turn enables Payment Predictor to recognize an overpayment or underpayment condition and then to take the appropriate action. This table describes the steps in the #BALANCE algorithm group:
|
Step |
Description |
|
ALGO_1 |
Sets the name of the algorithm within the group. It updates the payment for any payments applied by this algorithm. Type: Select Statement:
|
|
“THE INSERT” |
Populates PS_PP_MATCH_TAO. This step is usually named for the algorithm within the group but may be called anything. In this algorithm, the name of the first algorithm is BALGR. Type: Update/Insert/Delete Statement:
|
|
ALGO_X1 |
Does the system work after the process populates PS_PP_MATCH_TAO. It removes invalid items from PS_PP_MATCH_TAO and classifies the payment as either fully applied, over-applied, or under-applied. Runs a section called ALGRDONE. Type: Do When Statement:
|
|
ALGO_2 |
The name of the second algorithm in the group if more than one exists. Type: Select Statement:
|
|
“THE INSERT” |
Populates PS_PP_MATCH_TAO. This step is usually named for the algorithm within the group, but may be called anything. In this algorithm, the name of the second algorithm is BALNET. Type: Update/Insert/Delete Statement:
|
|
ALGO_X2 |
Does the system work for the second algorithm after the process populates PS_PP_MATCH_TAO. It removes invalid items from PS_PP_MATCH_TAO and classifies the payment as either fully applied, over-applied, or under-applied. Runs a section called ALGRDONE. Type: Do When Statement:
|
To understand how an item-summary-reference-based algorithm group works, examine #REFS. This algorithm group has one algorithm that selects only open items that exactly match the references supplied with a payment. When you scroll through the steps, you may notice that the steps have a pattern.
To help you understand how #REFS works, this table describes the steps.
|
Step |
Description |
|
ALGO_1 |
Sets the name of the algorithm within the group and updates the payment for any payments applied by this algorithm. |
|
MATCHTMP2 |
Clears the PS_PP_MATCH2_TAO table. |
|
ITEMREF |
Populates PS_PP_MATCH2_TAO. It is done once for each unique reference qualifier that is used by the payments to be applied. If a payment is in both PS_PP_MATCH2_TAO and PS_PP_MATCH_TAO, it removes it from PS_PP_MATCH2_TAO. Then it copies the data from PS_PP_MATCH2_TAO to PS_PP_MATCH_TAO. |
|
ALGR_A1 |
Removes invalid items from PS_PP_MATCH_TAO. |
|
ALGR_B1 |
Processes matches. |
|
ALGR_C1 |
Update payment status. |
|
ALGO_D1 |
Retrieves counts. |
|
ALGO_E1 |
Sets PP_PROC_FLAG to “1” and ends the matching process. |
The #REFS_NG algorithm group has algorithms that you can modify to deal with references that do not match items exactly. They are platform-specific and you should feel free to take advantage of any functions that your database allows. Because this algorithm group compares a partial ID and returns any possible matches, the processing time for this algorithm group is longer than other algorithm groups. Use this algorithm group only when there is no other way to create matches, and always set up the payment predictor method to generate a worksheet, where you review and finalize the payment.
The following table describes the two algorithms in the #REFS_NG algorithm group:
|
Algorithm |
Description |
|
FIRST8 |
Matches the first eight characters in the reference information to the first eight characters of the specified fields on the item in the database. You can change the parameters in the %substring from either side of the equation, depending on how you want to match.
|
|
MIDDLE7 |
Skips the first three characters and matches the middle seven characters in the reference information to the middle seven characters of the specified fields on the item in the database.
|
Deactivating an Algorithm in an Algorithm GroupThis section explains how to deactivate algorithms in an algorithm group that you do not want to use. For example, the #BALANCE algorithm group has two algorithms that are similar, but you only need one of them.
To deactivate an algorithm:
Open the AR_PREDICT2 Application Engine program in Application Designer.
Locate the name of the algorithm group in the sections.
Algorithm groups have names that start with # and appear first in the list.
Expand the algorithm group and locate the step (algorithm) that you want to disable.
Clear the Active check box to disable the algorithm.
Adding an Algorithm GroupYou can add an algorithm group by copying algorithms from an existing algorithm group. We recommend copying whenever possible. However, if copying is not permitted on the platform that you are using, you can write one yourself.
To add a new algorithm group:
Open the AR_PREDICT2 Application Engine program in Application Designer.
Select Insert, Section.
A new section titled Section1 appears in the list.
Type over the name of Section1 algorithm group.
The new name must start with #. For example: #NEW.
Save your work.
Copy algorithms from existing algorithm groups and paste them into the new algorithm group.
Each algorithm requires a minimum of three statements: name, insert, and post match system processing.
If the algorithm is customer-based, copy an existing algorithm that is most similar to one that you want to create.
If the algorithm is reference-based, copy #REFS.
To copy, right-click the section that you want to copy and select Copy.
To paste, right-click the section where you want to insert the new section and select Paste.
Copy and paste the SQL statements for each step.
To copy, right-click the appropriate action and select View SQL.
To paste, right-click the appropriate action folder in the new section and select Paste.
Modify the SQL as needed.
Using #DETAIL and #DTL_TLR for Partial Payments and DeductionsThis section has tips on using the #DETAIL or #DTL_TLR algorithm group. You must select one of these algorithm groups to process detail reference information that includes the amount of the item, as well as an item ID.
Typically, you use the #DETAIL algorithm group for payment-level adjustments and the #DTL_TLR group for partial payments and discounts. Both groups enable you to take deductions. The #DTL_TLR and #DETAIL algorithm groups enable you to specify the desired entry type and entry reason for handling exceptions.
Detail reference information for a particular payment is stored in the following fields of the PS_PAYMENT_ID_ITEM table:
|
Field |
Description |
|
ITEM_AMT |
The gross amount of the item selected to be paid. |
|
PAY_AMT |
The net amount of the item selected to be paid. |
|
DISC_TAKEN |
Either PAY_AMT or else both ITEM_AMT and DISC_TAKEN must be positive numbers. If all these amounts are provided, Payment Predictor uses only PAY_AMT.
Using #DETAIL and #DTL_TLR for Deductions
The #DETAIL and #DTL_TLR algorithm groups enable you to take deductions. For a deduction to occur, in the PAYMENT_ID_ITEM record, the ENTRY_USE_ID must be WS-08 (create a deduction). The record should also contain item reference information, including the business unit, customer ID, and item ID. The item may be an existing item. The only restriction is that the deduction cannot be for the open item that is selected for the current payment. Deductions associated with prior activity can be processed by the payment.
Using #DTL_TLR for Partial Payments and Discounts
If Payment Predictor runs a payment predictor method that contains the #DTL_TLR algorithm group, the processing of partial payments differs depending on how you setup the tolerances on the Receivables Options - Predictor Detail Options page and whether you selected the Partial Payment Switch field on the Bill To Options page for the customer.
If you select the Partial Payment Switch check box, the process does the following:
If the payment amount is less than the open balance amount minus the earned discount amount, the process does one of the following:
If the remaining amount is within the tolerances on the Receivables Options - Predictor Details Options page, it closes the item and creates a write-off or adjustment based on the setup.
If the remaining amount is greater than the tolerances on the Receivables Options - Predictor Details Options page, it makes a partial payment and leaves the remaining amount open on the item.
If the payment amount is greater than the open balance amount minus the earned discount amount, the process pays the item in full and uses the values that you entered on the Receivables Options - Predictor Details Options page to determine whether to write off or adjust an overpayment.
If you clear the Partial Payment Switch check box, the process uses the values that you entered on the Receivables Options - Predictor Details page to determine whether to write off or adjust an underpayment or overpayment.
For example, suppose that the tolerance amount is set at 50.00 USD and the percentage is set at 10 percent. If a payment of 90.00 USD is received after the payment term for the discount has expired for a 100.00 USD item, the payment will be within tolerance since the 10.00 USD short pay is less than the fixed tolerance amount of 50.00 USD and the calculated amount of 10 percent using 100 x 0.10. Therefore the 10.00 USD of the short pay amount is adjusted or written off based on what is specified using the Payment Predictor detail options.
A condition exceeds tolerance if it either exceeds the fixed tolerance amount or exceeds the tolerance percentage. In that case, you can set up Payment Predictor to take a different action for overpayments and underpayments.
Note. If an item does not qualify for an earned discount, but the Disc (discount) field is selected for the item on the Detail Reference Information page and there is a discount amount entered; the process takes the unearned discount. The process takes the unearned discount regardless of the Partial Payment Switch field setting.
To set up your system to use tolerances for partial payments and discounts, you must perform the following tasks:
Assign the #DTL_TLR algorithm group to payment predictor methods.
Select or clear the Partial Payment Switch check box for customers for whom you want to apply payments using the #DTL_TLR algorithm group on the Bill To Options page.
Assign a payment predictor method that runs the #DTL_TLR algorithm group to customers on the Bill To Options page or to business units on the Receivables Options - Payment Options page.
Assign the entry types and reasons for the #DTL_TLR algorithm group to the appropriate automatic entry types on the Automatic Entry Type - Selection page.
Define the discount tolerances and write-off limits for underpayments and overpayments on the Receivable Options - Predictor Detail Options page.
(Optional) Override the default system function to use for underpayments and overpayment and unearned discounts on the Receivables Options - Predictor Detail Options page.
See Also
Setting Up Automatic Entry Types
Selecting Payment Predictor Options
Entering Additional Billing, Purchasing, Payment, and Write-Off Options for Bill To Customers
Using the #OVERDUE Algorithm GroupThe #OVERDUE algorithm group handles payments for overdue charge line items. If you use the option to create overdue charges by item line, you can create payment predictor methods that use this algorithm group. You assign a sequence number to each entry reason for the overdue charge (FC-01) item entry type on the Item Entry Type - Selection page. Payment Predictor uses this sequence number to determine the order to pay the overdue charge line items. The #OVERDUE algorithm group handles payments based on certain conditions:
Payment Predictor applies payments and any credit amount available to all overdue charges first before the remaining amount is disbursed to the principal amount.
Payment Predictor applies a partial payment to the first item after the last fully paid item in the sequence if there are insufficient funds to pay for remaining open overdue charge line items.
The sequence is determined by due date in ascending order. If there is any credit amount available, Payment Predictor applies it as part of the payment.
To set up your system to use the #OVERDUE algorithm group, perform these tasks:
Set up the sequence number for each entry reason for the overdue charge item entry type.
Set up a payment predictor method containing the #OVERDUE algorithm group.
Assign a payment predictor method that contains the #OVERDUE algorithm group to customers.
Example: #OVERDUE Algorithm Group
This section provides an example of how payment predictor applies payments to overdue charge line items.
This table lists the sequence numbers that are assigned to the entry reasons for the automatic entry type for finance charges for this example:
|
Entry Reason |
Sequence Number |
|
ADMIN |
1 |
|
PNLTY |
2 |
This table lists items and finance charge line items that are open for a customer:
|
Item |
Line Number |
Due Date |
Entry Type |
Entry Reason |
Balance Amount |
|
IT_OC1 |
1 |
March 17, 2002 |
OC |
ADMIN |
16.16 USD |
|
IT_OC2 |
1 |
March 17, 2002 |
OC |
ADMIN |
32.32 USD |
|
IT_OC2 |
2 |
March 17, 2002 |
OC |
FIN |
32.32 USD |
|
IT_OC1 |
2 |
March 17, 2002 |
OC |
FIN |
16.16 USD |
|
IC_OC1 |
3 |
March 17, 2002 |
OC |
PNLTY |
16.16 USD |
|
IC_OC2 |
3 |
March 17, 2002 |
OC |
PNLTY |
32.32 USD |
|
IT_OC1 |
0 |
March 3, 2002 |
IN |
|
1000.00 USD |
|
IT_OC2 |
0 |
March 3, 2002 |
IN |
|
2000.00 USD |
This table lists the sequence numbers that Payment Predictor would apply to the items to determine the payment order:
|
Item |
Line Number |
Due Date |
Overdue Charge Sequence Number |
|
IT-OC1 |
1 |
March 17, 2002 |
1 |
|
IT_OC2 |
1 |
March 17, 2002 |
1 |
|
IT_OC1 |
3 |
March 17, 2002 |
2 |
|
IT_OC2 |
3 |
March 17, 2002 |
2 |
|
IT_OC1 |
0 |
March 3, 2002 |
9 |
|
IT_OC2 |
0 |
March 3, 2002 |
9 |
|
IT_OC1 |
2 |
March 17, 2002 |
9 |
|
IT_OC2 |
2 |
March 17, 2002 |
9 |
This table shows what the results would be if you applied a 50.00 payment to the customer.
|
Payment Amount |
ITEM ID |
ITEM Line |
TYPE |
|
16.16 USD |
IT_OC1 |
1 |
PY |
|
32.32 USD |
IT_OC2 |
1 |
PY |
|
1.52 USD |
IC_OC1 |
3 |
PY |
See Also
Reviewing Payment Predictor and Special ConditionsThis section has background information on how algorithms handle special conditions.
To handle special conditions, Payment Predictor uses statements that execute within the algorithm group or within sections that are done from the algorithm group. This enables Payment Predictor to break up processing into pieces between which the answer set can be modified. Payment Predictor uses a DO SELECT that is driven by the same SQL statement to execute the statements.
To process a reference-based algorithm, Payment Predictor builds a list of references for all payments in the run. Then for each type of reference used, it modifies and executes the algorithm dynamically. For example, if any payments in the run have ITEM references, it modifies the SQL to “AND I.ITEM = D.REF_VALUE AND D.REF_QUALIFIER_CODE = ‘I’.” We recommend that you use an index based over PS_ITEM for each type of reference that you use on a regular basis.
In the ID_ITEM section, Payment Predictor uses the reference to identify a customer by using the item. In the ITEM_REF algorithm, a DO SELECT drives a DO of the section RLOOP. This populates the PS_PP_MATCH_TAO temporary table using the same two lines and %BIND variables concatenated at the end of the basic insert that joins the payment, items, and item references.
AND X.REF_QUALIFIER_CODE = %BIND(REF_QUALIFIER_CODE) AND X.REF_VALUE = I.%BIND(FIELDNAME, NOQUOTES)
Limiting Items Applied by References to Customer-Identified Items
Normally, a payment with an item reference pays items regardless of the item's customer ID. In cases where you receive both reference information and customer identification, Payment Predictor restricts the items applied by references to the customers identified through the use of an algorithm group called #REFS_ONE. The #REFS_ONE algorithm group contains a section, ONE_CUST, that deletes from the PS_PP_MATCH_ TAO record those rows in which the customer is not part of the remit from group associated with the MICR ID or the customer. This statement has no effect if the MICR ID or customer ID is invalid.
Ordering by Oldest Due Date First
Payment Predictor loads all the customer items into the PS_PP_MATCH_TAO record to perform oldest first processing (ordering items with the oldest item first). It loops through the items, record by record, in oldest due date first order and then deletes any unused records. Payment Predictor uses two algorithm groups that accomplish the same result in the same manner. They selectively eliminate items from the PS_PP_MATCH_TAO record with an ordering option. The two algorithms are:
#OLDEST1: Orders open items from oldest to latest due date including credit items.
#OLDESTC: Includes all credits as part of the payment first, then applies payments.
Orders the remaining items from oldest to latest due date.
If you are using the #OLDEST or #OLDESTC algorithm, Payment Predictor always makes partial payments on the last item that depletes the remainder payment amount for bill to customers when the payment amount does not exactly match the sum of the matched items. If you are using DTL_TLR (detail with tolerance algorithm), Payment Predictor makes partial payments when the payment amount does not exact match item balance amount and if the customer has been set up for partial payments on the Bill To Options page.
See Using #DETAIL and #DTL_TLR for Partial Payments and Deductions.
If your organization receives payments that are prepayments for specific invoices that you created in your billing application, you can set up Payment Predictor to create Prepay Items (WS-04). To take advantage of this feature, you must receive the invoice number in the ITEM field on the PS_PAYMENT_ID_ITEM record. You must also activate the NOTFOUND step (algorithm) in the DETAIL section (algorithm group) of the AR_PREDICT1 Application Engine process. You must also use a payment predictor method that uses detail references.
Using this feature is the same as creating a prepayment item on the payment worksheet. Payment Predictor applies the prepayment to an item later—after you enter an item in Receivables that has an item ID that matches the value that you received in the ITEM field in the PAYMENT_ID_ITEM record.
Defining Payment Predictor MethodsTo define payment predictor methods, use the Predictor Method (PP_METHODS) and Predictor Method Review (METHOD_REVIEW) components.
This section provides an overview of payment predictor methods and discusses how to:
Define a payment predictor method.
Review an example of a payment predictor method.
Understanding Payment Predictor MethodsA payment predictor method tells Payment Predictor how to handle the different situations it encounters during processing. Each method consists of a series of conditions and actions based on remittance information. You can define as many methods as you want, but keep the methods as simple as possible and tailor them closely to the remittance patterns of your customers to optimize the efficiency of auto matching. Although Receivables ships with sample methods, you must create your own methods and assign them to a setID or individual customers.
Ideally, the methods that you define should enable Payment Predictor to apply all your regular payments, leaving only the exceptions to be applied online using payment worksheets. To minimize the number of exceptions, your methods must reflect the ways your customers pay you. You can assign methods to an entire business unit or to specific customers, so that you can tailor your methods to groups of customers with similar payment practices.
If you have a mixed situation with some overrides, it is much easier to diagnose problems if your methods are stored under one setID. Deposit business unit values and item business unit values, if different, should both point to the same, common TableSet. PeopleSoft also recommends that you keep the number of methods that you use to a minimum. Start with one method that is specified at the deposit business unit level. Then add methods for handling customers that consistently pay you in a way that is different from your other remit from customers.
When you define a payment predictor method, consider the reference information that comes with the payment and how it can be used to match the payment to the customer. The type of reference information determines which algorithms you use.
We recommend that the first algorithm group in a method apply the most payments.
Important! If you use the vendor rebate option in Purchasing or the claim back option in Order Management, create payment predictor methods that do not write off the remaining balance for items. Assign those methods to the business unit that is set up for vendor rebate and claim back processing. Use the Claims Management Workbench in Purchasing or Order Management to handle write-offs. This enables the system to determine whether the write-offs meet the write-off tolerances for claim processing.
Payments Without Reference Information
For payments with no reference information, use the following algorithm groups.
#BALANCE
#COMBOS
#OLDEST1
#OLDESTC
#OVERDUE
#PASTDUE
#STATMNT
Payments with Summary Reference Information
For payments with summary reference information (that is, references with item identification but no amount), use the following algorithm groups:
#REFS
#REF_ONE
#REF_NG
If you use the Cash Drawer Receipts feature to record payments for counter sales, use one of these algorithm groups in your payment predictor method to apply the payments.
Note. Use an algorithm group for detail references if you receive payments with summary reference information that pay for multiple line items with the same item ID.
Payments with Detail Reference Information
For payments with detail reference information (that is, references with item identification and amount), use the following algorithm groups:
#DETAIL
#DTL_TLR
See Also
Understanding Payment Predictor Modes
Understanding Sample Algorithm Groups
PrerequisitesYou must define the algorithm groups for payment methods, because methods use algorithm groups to select items.
Pages Used to Define a Payment Predictor Method
|
Page Name |
Object Name |
Navigation |
Usage |
|
PP_METHODS_TABLE |
Setup Financials/Supply Chain, Product Related, Receivables, Payments, Predictor Method, Predictor Method |
Define a payment predictor method. |
|
|
PP_METHODS_REVIEW |
Setup Financials/Supply Chain, Product Related, Receivables, Payments, Predictor Method Review, Review |
View, but not change, an existing payment predictor method. The fields on this page are identical to those on the Predictor Method page. |
Defining a Payment Predictor Method
Access the Predictor Method page.
Step
Each step consists of one or more payment conditions; each condition has an action. The step number determines the order in which the step is processed in the method.
Click the Order buttons to change the order of the steps.
Condition and Action
A step must have at least one condition. You can assign up to seven conditions to a step and select one of five actions for each condition. The conditions cannot conflict with each other. The number of the condition determines the order in which it will be processed within the step. Values are:
First...
Any Overpayment
Overpayment Exceeds
Overpayment Is Less Than
Any Underpayment
Underpayment Exceeds
Underpayment Is Less Than
Note. If you use Any Overpayment or Any Underpayment, you cannot use the tolerance choices for overpayments or underpayments that exceed or fall short of a certain amount. The reverse is also true. If you use Overpayment Exceeds, Underpayment Exceeds, or Underpayment Is Less Than, you cannot use Any Overpayment or Any Underpayment. The exception is the #DTL_TLR algorithm group. For the #DTL_TLR algorithm group, you should not select any of the underpayment or overpayment conditions. The conditions for exceptions for this algorithm group are defined using the Predictor Detail Options page.
|
Amount or Percent |
If you select an overpayment or underpayment, enter values in one or both of these fields. For example, you can specify an action when an overpayment is less than 100.00 EUR or less than 12 percent of the payment. If you specify both an amount and a percent, the system processes the overpayment or underpayment as long as one of the tolerance criteria is met. You can specify only one set of tolerance criteria for each condition. Enter the currency for the amount to enable the system to convert amounts properly when determining whether a write-off amount meets the tolerance. |
You must select one of the following actions:
Note. If you select Apply To Control Customer and Payment Predictor cannot identify any customers, Payment Predictor determines whether the default method associated with the deposit business unit indicates Apply To Control Customer when the customer identification is missing or is set to Doesn’t Matter.
Reviewing an Example of a Payment Predictor MethodThis section includes an example of a summary reference Payment Predictor method.
The sample method contains five steps. Each step is based on remittance characteristics: how to structure Payment Predictor’s actions based on the results of customer identification and the presence or absence of summary reference information. Each step considers various payment conditions and each condition has an associated action.
The example assumes that you receive a mix of payments, some with payment summary references—references without associated item amounts—and some without summary references. It places the steps using algorithm groups for payments with references first, because it is normally more efficient to execute those steps first.
Note. To create an example of a detail reference method, change the algorithm group in Step 1 to one of the algorithm groups for detail references.
Step 1
In Step 1, the method’s remittance conditions take into account payments with references. Regardless of whether customers are identified, if payment summary references are supplied, Payment Predictor runs the algorithms in the #REFS group.
For the Customers Identified field, select Doesn’t Matter. For References Supplied, select Summary.
|
Step 1, Condition 1 (First) |
Select Execute Algorithm Group, then select #REFS. |
|
Step 1, Condition 3 (Overpayment Exceeds) |
Enter a value in the Amount or Percent fields. Example: an amount of 100.00. Select Release The Payment. If an overpayment exceeding the tolerance occurs, the method directs Payment Predictor to release the payment for processing by another relevant step. This step shows that when a large variance occurs, the wrong item may have been referenced. In this case, it is better to release the payment than to apply it to the wrong item, which may belong to a different customer. Another possibility is that a mix of valid and invalid references caused the large overpayment. If most references are valid or most payments have only one reference, this use of the overpayment condition could be helpful. |
|
Step 1, Condition 4 (Overpayment Is Less Than) |
Enter a value in the Amount or Percent fields. Example: an percent of 15. Select Generate An Item and select the system function WS-05 to place an amount on account. The same remittance conditions apply here as in the previous condition. If an overpayment is less than the specified tolerance, Payment Predictor creates an on-account item. You can then use this item to apply to another item on a maintenance worksheet. Notice that the tolerance amounts are the same as for Condition 3. Use the same amounts for both of the overpayment conditions so Payment Predictor can handle all overpayment amounts. It is not necessary to build a worksheet for online review; just enable the resulting payment group to be processed the next time the Receivable Update Application Engine process (ARUPDATE) runs for the appropriate business unit. |
|
Step 1, Condition 6 (Underpayment Exceeds) |
Enter a value in the Amount field. Example: 5.00. Select Generate An Item and select the system function of WS-08 to create a deduction. The same remittance conditions apply here. If an underpayment occurs that is greater than the specified amount, Payment Predictor creates a deduction for the difference and builds a worksheet for online review. To define this condition and the following one, an online payment application scenario was considered and Payment Predictor was directed to emulate that action during background processing. |
|
Step 1, Condition 7 (Underpayment Is Less Than) |
Enter a value in the Amount field. Example: 5.00. Select Generate An Item and select the system function of WS-11, write off an underpayment. The same remittance conditions apply here. If a very small underpayment occurs, Payment Predictor writes off the amount of the underpayment. It is not necessary to build a worksheet for online review; just enable the resulting payment group to be processed the next time the Receivable Update process runs for the appropriate business unit. |
Step 2
The second step in the sample method executes regardless of the results of customer identification and only if you did not receive references.
For Customers Identified, select Doesn’t Matter to ask Payment Predictor to process any payment for which at least one customer was identified. For References Supplied, select No.
|
Step 2, Condition 1 (First) |
Select Execute Algorithm Group, then select #COMBOS. This algorithm group has three algorithms, two of which are active in the sample data. The two active algorithms look for a single debit or a single debit net of earned discount—belonging to one of the identified customers—that matches the payment amount. This approach is useful if your remittance analysis indicates that your customers often pay one open item at a time and the open items are usually for different amounts. If you do not offer discounts, inactivate the algorithm that evaluates earned discounts. If your customers often pay two items at a time, consider activating the algorithm that looks for any two items combined that match the payment amount. |
Step 3
Step 3 repeats the same remittance conditions as Step 2. It executes regardless of the results of customer identification and only if you did not receive references.
This step is useful for customers who often pay their entire open item balance. An algorithm variation exists for handling earned discounts.
For Customers Identified, select Doesn’t Matter so Payment Predictor processes any payment for which at least one customer is identified. For References Supplied, select No.
|
Step 3, Condition 1 (First) |
Select Execute Algorithm Group, then select #BALANCE. |
Step 4
Step 4 repeats the same remittance conditions as Steps 2 and 3. It executes regardless of the results of customer identification and only if you did not receive references.
For Customers Identified, select Doesn’t Matter to ask Payment Predictor to process any payment for which at least one customer was identified. For References Supplied, select No.
|
Step 4, Condition 1 (First) |
Select Execute Algorithm Group, then select #PASTDUE. |
This step shows how the order in which algorithms are executed must be taken into consideration. It is possible that more than one algorithm group could apply to the same payment.
For example, if a remit from group has only one open item (for a new or low-volume customer), then either #COMBOS or #BALANCE would work. If all of the open items are past due (customer has not bought anything recently), then #BALANCE or #PASTDUE would work. Under these circumstances, it is advisable to order the algorithms from most to least efficient. This results in the order #COMBOS, followed by #BALANCE, and then #PASTDUE.
Other factors, such as the number of payments that a given algorithm group applies, are also important. If #PASTDUE could apply to 90% of payments, #BALANCE 10%, and #COMBOS 10% (the total can exceed 100%), then an option is to place #PASTDUE first. These decisions must be made on an individual basis, looking at both payment profiles and enabled algorithms.
When you start using Payment Predictor, begin by ordering steps according to efficiency. If production runs demonstrate that most payments are applied in a step far down in the method, reorder the steps until you establish an optimal configuration.
Step 5
Step 5 executes regardless of remittance conditions. It places any payments that steps 1 through 4 did not apply on account for a control customer. It acts as a catch all for payments that it could not identify.
For Customers Identified, select Doesn’t Matter to enable Payment Predictor to process any payment for which at least one customer is identified. For References Supplied, select Doesn’t Matter.
|
Step 5, Condition 1 (First) |
Select Apply to Control Customer, then select a business unit and customer ID, selecting 99999 or another out-of-range identifier. Select the Worksheet check box. Take a similar approach if your business practices call for posting all unidentified cash to a control customer. |
Setting Up Parallel ProcessingThis section provides an overview of parallel processing for Payment Predictor and discusses how to:
Define the maximum instances in PSAdmin.
Define the maximum concurrent processes for the server.
Define the number of parallel processes.
Add more parallel processes to the AR_PP multiprocess job.
Add additional Payment Predictor process definitions.
Understanding Parallel Processing for Payment PredictorReceivables enables you to process multiple Payment Predictor processes in parallel to achieve higher performance. You initiate the processes using one run control and the process automatically divides the work between the number of partitions that you specify in your setup.
The Payment Predictor multiprocess job (ARPREDCT) includes:
The AR_PREDICT1 process.
The AR_PP multiprocess job.
The following diagram illustrates how the process works if you have four partitions.
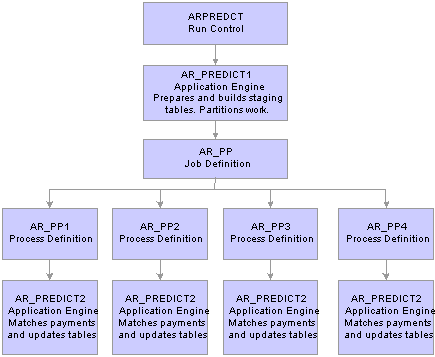
Payment Predictor parallel processes
When you use PeopleSoft Enterprise Process Monitor to check the status of the process, you view the status of the AR_PREDICT1 process and each process within the AR_PP multiprocess job. The system does not indicate that the Payment Predictor multiprocess job (ARPREDCT) is successful until each parallel process completes. The Job Message Log Summary page summarizes all the individual parallel process message log messages for the entire ARPREDCT job.
The AR_PREDICT1 process acts as a preprocessor for the actual payment matching process and also:
Gathers all the qualified data for processing.
Places the qualified data in temporary tables.
Partitions the data between the child processes.
Initiates the AR_PP multiprocess job that starts child processes in parallel.
The distribution of the data among the child or parallel processes is based on the composition of the data and the number of parallel processes. The process attempts to spread the data volume evenly among the processors. The staging phase takes a little longer, but the overall processing time is faster because multiple children processes run concurrently. You should balance the decision of using parallel processing or single thread processing based on the volume of data and the hardware capacity to get the maximum benefit from this feature.
The AR_PP multiprocess job contains all the Application Engine process definitions that you use for parallel processing, such as AR_PP1. Each process definition calls the AR_PREDICT2 Application Engine process, which actually matches the payments, updates the application tables, and performs table cleanup before the process ends.
Receivables delivers eight process definitions—AR_PP1 through AR_PP8. If you want to run more than eight partitions of the Payment Predictor process at once, you must define additional process definitions. Use the AR_PP1 process definition as an example.
The standard setup for the AR_PP multiprocess job is to run a single threaded process and contains only the AR_PP1 process definition. If you want to use parallel processing, you must assign additional process definitions to the job definition. You must also specify the number of partitions that your organization will use. You might have to experiment with the number of partitions that works for you. We recommend that you assign just a couple of additional partitions and increase the number, if needed.
You might also have to override the server settings for your organization. By default, you can run up to three instances of a process at one time. If you want to run additional instances, you must change your configuration. If you also use parallel processing for the Aging (AR_AGING), Statements (AR_STMTS), and Receivable Update (AR_UPDATE) processes, the maximum instances applies to those processes, as well. For example, if you want to run eight instances for the Receivable Update process and four for the Payment Predictor process, you must configure your server for eight instances.
Pages Used to Set Up Parallel Processing
|
Page Name |
Object Name |
Navigation |
Usage |
|
SERVERDEFN |
PeopleTools, Process Scheduler, Servers, Server Definition, Server Definition |
Define the maximum concurrent processes for Application Engine processes. |
|
|
PARALLEL_AR_SBP |
Set Up Financials/Supply Chain, Install, Installation Options, Receivables Then click the Parallel Processing Options link. |
Specify the exact number of parallel processes or partitions that you want for Payment Predictor. |
|
|
PRCSJOBDEFN |
PeopleTools, Process Scheduler, Jobs, Job Definition, Job Definition |
Add additional Payment Predictor process definitions to run the AR_PP multiprocess job. |
|
|
PRCSDEFN |
PeopleTools, Process Scheduler, Processes, Process & Definition, Process Definition |
Add additional Payment Predictor process definitions if you need to run more than eight parallel processes. |
Defining the Maximum Instances for PSAdminOpen the PSAdmin tool on your server to change the configuration settings.
To change the maximum instances:
Scroll to the section titled Values for config section – PSAESRV.
The section looks as follows:
Values for config section - PSAESRV. Max Instances = 3. Recycle Count=0 Allowed Consec Service Failures=0.
Change the value for Max Instances to the maximum number of parallel processes that you want to run at once.
Defining the Maximum Concurrent Processes for the ServerAccess the Server Definition page.
|
Process Type and Max Concurrent |
For the Application Engine process type, enter the maximum number of parallel processes that you run at once. This figure must be the same or greater than the maximum instances that you defined for PSAdmin. |
See Also
Enterprise PeopleTools PeopleBook: PeopleSoft Process Scheduler
Defining the Number of Parallel Processes
Access the AR Parallel Processing Options page.
|
Parallel Process and Maximum Partitions |
Enter the exact number of partitions or parallel processes that you want to run for the AR_PREDICT parallel process. |
Adding More Parallel Processes to the AR_PP Process Job
Access the Job Definition page for the AR_PP job.
|
Run Mode |
Always select Parallel. |
|
Process Type and Process Name |
Enter Application Engine for the type and select from AR_PP2 to AR_PP8 for each separate partition or process that you want to run. If you define additional process definitions, select the name of the definitions that you added. Note. You must have the same number of rows in the process list as you enter in the Maximum Partitions field on the AR Parallel Processing Options page. |
|
Run Always on Warning and Run Always on Error |
You must select these check boxes. |
See Also
Enterprise PeopleTools PeopleBook: PeopleSoft Process Scheduler
Adding Additional Payment Predictor Process DefinitionsAccess the Process Definition page.
Complete the fields on this page and the other pages in the Process Definition component (PRCSDEFN) to match the AR_PP1 process definition with two exceptions:
Use another name.
Use another description.
Use this format for the name: AR_PP#, for example AR_PP9.
See Also
Enterprise PeopleTools PeopleBook: PeopleSoft Process Scheduler
Selecting Payments for Payment Predictor ProcessingWhen you set up Payment Predictor methods, establish a hierarchy for processing business units, customers, deposits, and payments. This table describes how you can further refine the process by excluding specific customers or payments.
|
Defaults |
Page Used to Set Default |
What Defaults Affect |
Turn On/Off |
Assign Method |
|
TableSet |
Receivables Options - Payment Options |
Business Units Determines which payment predictor method the system uses as the default for a business unit. |
N/A |
X |
|
Bank Account |
Information |
Deposits Payment Predictor evaluates payments received electronically, as well as those entered online. When the system receives a payment through a payment interface, it checks the bank account’s attributes to see whether payments from this bank account should use Payment Predictor as their default application approach. The associated bank account that uses Payment Predictor should have the PP_SW field on the PS_BANK_ACCT_DEFN table set to Y. |
X |
N/A |
|
Customer |
Bill To Options |
Bill To Customers Enables you to override the payment predictor method set at the business unit level for this customer. Supports putting an individual customer on hold to exclude its items from consideration by Payment Predictor. |
X |
X |
|
Payment |
Express Deposit Payments Regular Deposit Payments Worksheet Selection |
Payments Determines if Payment Predictor should apply an individual payment from an electronic payment or from an online payment. This choice overrides the on and off setting at the TableSet or bank account level. To include or exclude an entire deposit for Payment Predictor processing, you must take action for each payment in the deposit. Although usually not done, it is possible to use Payment Predictor from the express deposit pages. Enter reference information, and then select Payment Predictor. |
X |
N/A |
See Also
Applying Payments Using Payment Worksheets
Entering Additional Billing, Purchasing, Payment, and Write-Off Options for Bill To Customers
Reviewing Payment Predictor Temporary Tables and SectionsThis section discusses how to:
Review temporary tables.
Review Payment Predictor sections and SQL statements.
Reviewing Temporary Tables
As an Application Engine-based program, Payment Predictor makes extensive use of set processing and temporary tables. This design improves performance and enhances your ability to modify processing for your environment.
Set processing is a method of manipulating data that operates on more than one row at a time. It is not a SELECT, FETCH, and UPDATE approach; rather, it inserts, updates, and deletes rows in sets. For example, Payment Predictor runs an algorithm group for all payments in all business units that use the current method and meet the remittance conditions of the current step.
The Payment Predictor uses cursor-based processing with reuse being on to avoid data contention and improve performance in support of the parallel processing.
Each of the temporary tables has PROCESS_INSTANCE as the high-order key to enable multiple Payment Predictor jobs to run on the server in parallel without interference.
The temporary tables are organized according to logical levels of data: payments, customers, items, steps, and matches.
Payment Predictor uses the following key temporary tables:
|
Table |
Description |
|
This table is the first table Payment Predictor populates. It contains one row for each payment processed. The PREPARE section populates this table. Payment Predictor processes only payments selected for Payment Predictor (PS_PAYMENT.PP_SW = Y) that are in balanced deposits (PS_DEPOSIT_ CONTROL.BAL_STATUS = I) for requested business units. Keys: PROCESS_INSTANCE, DEPOSIT_BU, DEPOSIT_ID, PAYMENT_SEQ_NUM. If any rows exist in PS_PAYMENT_ID_ITEM, the system sets PP_REF_STATUS to Y—references supplied. This is important because Payment Predictor processes payments with reference information differently than payments without reference information. Note. Payment Predictor changes the initial value of Y to N—no references supplied—if it cannot identify any customers based on the reference information. In other words, a value of N might be interpreted as no references supplied or that all references supplied are invalid. Payment Predictor sets the value of PP_MICR_STATUS based on an analysis of the contents of PS_PP_CUST_TAO. The field name is somewhat misleading; the values placed in the field refer to the broader results of customer identification and not just the presence of a MICR ID. End result values are:
Payment Predictor stores the method and the setID for the method that was used to process the payment on this table. The PP_APPL_STATUS and PP_DISPOSITION fields contain information on the status of a payment and whether it has been applied or whether it requires a worksheet. |
|
|
This table contains one row for each customer identified by each payment. Keys: PROCESS_INSTANCE, DEPOSIT_BU, DEPOSIT_ID, PAYMENT_SEQ_NUM, CUST_ID (duplicates allowed) Customers are identified using one or more of the following:
Note. When a payment has reference information, Payment Predictor does not use the customer identification information placed on the PS_PP_CUST_TAO table. Instead, it uses the reference qualifier and reference information to find the corresponding items on PS_ITEM. The PS_ITEM records contain the business unit and the customer identifier. Payment Predictor uses the business unit and customer identifier to determine the appropriate customers and related remit from customers. |
|
|
This table contains one row for each item considered for payment application. If the payment does not have reference information (rows in PS_PAYMENT_ ID_ITEM), Payment Predictor loads all open items for all customers in PS_PP_CUST_TAO into this table. Later, non-reference-based algorithms that are associated with a method evaluate the data in PS_PP_ITEM_TAO. Note. An algorithm does not have to use this table as the basis for its evaluation. For example, suppose that the reference-based algorithms obtain information directly from PS_ITEM, bypassing PS_PP_ITEM_TAO completely. Payment Predictor then runs a reference algorithm by inserting a row for each item selected by that algorithm directly into PS_PP_MATCH_ TAO. It then backloads the matches into PS_PP_ITEM_TAO to maintain consistency between these two tables. |
|
|
This table contains one row for each step, condition, and action of each method that is processed in a run. The SBLD module populates this table and then executes each step in turn. SBLD drives the payment application process. After the process loads all steps for all identified methods into PS_PP_STEP_TAO, this module does a SELECT, FETCH, and DELETE of each method step in order. The actions associated with a step are performed simultaneously against all payments that have not been processed (or have been released), that have been assigned to the current method by Payment Predictor, and that meet the remittance pattern specified for the step. When the Payment Predictor process completes, this table should be empty (because all steps should have been processed). |
|
|
The process uses this table to evaluate overpayment and underpayment conditions. This table contains one row for each item to be paid by the payment or to be included on a payment worksheet. It is populated by an algorithm (or by WBLD when you use the Generate A Worksheet option). It might also contain one additional row for each payment that represents a new item generated by the Payment Predictor. It is actually the join between this table and PS_PP_ITEM_TAO that represents the transactions generated by a payment for a worksheet or pending group. |
|
|
The process uses this table to evaluate the sequence of overdue charge entry reasons in the ENTRY_REASN_TBL. |
See Also
Defining Receivables Installation Options
Reviewing Payment Predictor Sections and SQL StatementsThe Payment Predictor multiprocess job (ARPREDCT) runs two Application Engine processes—AR_PREDICT1 and AR_PREDICT2. Each Application Engine process runs a collection of SQL statements that are run by Application Engine. The AR_PREDICT2 process contains algorithm groups that represent sections. Each algorithm in the section represents a step that is either an SQL statement or the DO of another section. If you want to DO a section more than once, you use a DO SELECT. The processes perform the section you specify once for each row the select returns. It places values returned by the select in %BIND variables and references them by name in subsequent SQL statements.
The AR_PREDICT1 process prepares the staging tables and populates the temporary tables for the second multiprocess job. The staging tables are PS_PP_ITEM_TMP, PS_PP_CUST_TMP, and PS_PP_PYMNT_TMP, and they are images of the tables PS_PP_ITEM_TAO, PS_PP_CUST_TAO, and PS_PP_PYMNT_TAO. The staging tables populate the temporary tables used by the child processes. The AR_PREDICT2 process uses the information in the temporary tables to generate the groups and worksheets.
The AR_PREDICT2 process flow has four stages:
Executing method steps.
Generating transactions.
Update tables and status.
Release process instances on tables.
This section provides background information about the sections in the AR_PREDICT1 and AR_PREDICT2 Application Engine processes.
AR_PREDICT1 - Preparing Temporary Tables
This table describes the sections that prepare temporary tables:
|
Section |
Description |
|
PREPARE |
Builds the temporary tables PS_PP_PYMNT_TAO and PS_PP_ITEM_TAO. For payments containing no references or completely invalid references, (PS_PP_ PYMNT_TAO.PP_REF_SW = N), it loads all items for the customers identified through PS_PAYMENT_ID_CUST into PS_PP_ITEM_TAO. |
|
ID_ITEM |
Populates the temporary table, PS_PP_CUST_TAO, with customer identification information for payments with references (PS_ PYMNT_TAO.PP_REF_ STATUS = Y). Platform-specific codes can apply in this section. First, Payment Predictor determines a list of the types of references that it uses for all payments in the run. Then for each type of reference it uses, it builds a dynamic SQL statement to insert a row into PS_PP_CUST_TAO for each payment. For each type of reference, it runs two SQL statements based on the algorithms CUSTMP1 and CUSTMP2. For example, if ITEM references were included in any payments in the run, the module would concatenate “AND X.REF_ QUALIFIER_CODE = ‘I’ AND X.REF_VALUE = I.ITEM)” to the end of the statements and run the statements. Done from PREPARE as a DO SELECT, ID_ITEM.
Payment Predictor accomplishes the same results without a special module for the dynamic SQL. All the SQL is dynamic, and Payment Predictor uses the Application Engine bind variables that are returned from the DO SELECT.
|
|
ID_CUST |
Populates the PS_PP_CUST_TAO temporary table with customer identification information for payments with MICR or customer references. Also done from PREPARE. Platform-specific codes can apply in this section. |
AR_PREDICT2 - Executing Method Steps
This table describes the sections that run method steps:
|
Section |
Description |
|
SBLD |
This section builds the PS_PP_STEP_TAO temporary table and then executes each step in turn. First, it inserts one row for each step, condition, and action of each method needed to process all payments for all business units requested. For example, if the step has a condition that runs an algorithm and then generates an adjustment for an underpayment, it inserts two rows into PS_PP_STEP_TAO. It deletes each row upon completion; this table should be empty at the end of a normal run. After the PS_PP_STEP_TAO table is created, the second phase begins. |
|
STEP |
The Step Manager, done from SBLD with a DO SELECT. Depending on the step and condition that the system is processing, the appropriate section is done. |
|
GENITEM |
Executed for each Generate An Item step. It might generate items based on the criteria specified in the method and on the condition of the payment. |
|
WBLD |
Executed for each Generate A Worksheet step. It might generate worksheets based on the criteria specified in the method and on the condition of the payment. |
|
CNTL_ACT |
Executed for a control account step. |
|
RELEASE |
Executed for each release. The payment step uses only the temporary tables. It releases a payment that an algorithm has attempted to apply, enabling subsequent method steps that match the remittance profile to process the payment. When an algorithm finds any items to apply for a payment, another algorithm (or method step) does not consider that payment for application unless a Release The Payment step releases it. |
|
ALGR |
Not a true section. A dynamic DO performs the actual run of the SQL contained in the algorithm group, and the section that is run is the name of the algorithm group. The name of an algorithm group must begin with a # and must match the name of a section. An algorithm is a group of statements in a section. When an algorithm populates PS_PP_MATCH_TAO, it must set the value of PP_PROC_FLAG to 0. Subsequent statements included in the algorithm group allow you to further adjust or refine the answer set contained in PS_PP_MATCH_TAO to:
|
|
ALGRDONE |
Performs system processing after an algorithm populates PS_PP_MATCH_TAO. This includes handling the bulk of the Payment Predictor hold logic, executing the Check Pending option, and eliminating duplicate items from being selected. After it is called, all items selected end up with PS_PP_MATCH_TAO. PP_PROC_FLAG = 1. This switch changes to 2 after the group of steps is completed—after an Execute Algorithm and then over- and underpayment clauses. ALGRDONE appears in sections at the points where the answer set can be modified. Receivables implements this in the algorithm groups of #BALANCE, #COMBOS, #PASTDUE, and #STATEMNT. |
AR_PREDICT2 - Generating Transactions
This table describes the sections that generate transactions:
|
Section |
Description |
|
UPDM |
Updates the matches. This is required to assign sequence numbers needed for building the PS_PENDING_ITEM and PS_PAYMENT_ITEM tables. This is a SELECT, FETCH, and UPDATE operation. UPDM performs other functions, including building deposits and payments generated during the run, making an additional pass for the check pending option, and handling the orphan payments that have not been processed. In addition, it excludes items that have been selected but that have a different currency from the payment. |
|
PGEN |
Generates payment worksheets, group control, and pending items, as needed. These are all set mode operations—a series of SQL statements run, each creating worksheets for a subset of payments. |
|
PUPD |
Performs a SELECT, FETCH, and UPDATE of each payment being processed in this run and updates the PS_PAYMENT table accordingly. PUPD exists as an individual section, because it can be replaced with a stored procedure on some SQL platforms. |
|
TERMINATE |
Calculates and logs messages for the payment totals and payment amounts either applied, generated to worksheets, or released. Releases the process instances on tables used. |