 Understanding Character Sets
Understanding Character Sets
This chapter provides overviews of character sets and selecting character sets and discusses how to:
Select character sets.
Validate field length.
Handle international characters in PeopleTools.
Detect and convert characters.
Understanding Character Sets
This section discusses:
Character sets.
Common character sets.
The Unicode standard.
Non-Unicode character sets.
Character sets in the PeopleSoft Pure Internet Architecture.
 Character Sets
Character SetsBefore you install your PeopleSoft system you must select an appropriate character set for PeopleSoft client workstations, application servers, and database servers.
A character set, also known as a codepage, is an ordered set of characters in which each character is mapped to a numeric index, called a codepoint. This codepoint stores character data in a computer system. Many hundreds of character sets exist. Some are international standards, sanctioned by the International Organization for Standardization (ISO), some are country-specific standards, and others are not standardized at all, but are specific to a particular computer system vendor. Given the number of separate computers that are involved in a typical PeopleSoft installation, it is likely that your system uses several different character sets.
Common Character SetsAlthough there is general agreement on the content and arrangement of most character sets, especially those that are standardized by the ISO, many different names are used by vendors and software packages for similar or identical character sets. US-ASCII encodes the basic characters and symbols that are needed to write the English language. However, US-ASCII is limited to 127 characters and cannot represent many characters that are needed by Western European languages, such as French and German, let alone ideographic languages, such as Japanese and Chinese, in which each character represents a word or concept. Many character sets, however, include all US-ASCII characters in addition to their other characters.
Note. To display extended Japanese characters install JDK 1.4.2_11+.
The following table illustrates just a few common character sets that you are likely to encounter and some of the names that are used by different vendors to refer to them:
|
Character Set |
Description and Comments |
Type |
PeopleSoft and Structured Query Report (SQR) Name |
Oracle database management system (DBMS) Name |
Microsoft Windows Name |
|
ISO 8859-1 |
Western European Latin-1. Contains characters that are required to represent Western European languages. However, does not include the euro symbol, the trademark (TM) symbol, or the oe ligature. |
ISO |
LATIN1 or ISO_8859-1 |
WE8ISO8859P1 |
CP28591 |
|
Microsoft Codepage 1252 |
Microsoft Codepage 1252 - Western European. Very similar to ISO 8859-1, except for the inclusion of additional characters. Includes the euro symbol, trademark (TM) symbol, and oe ligature, but using a different codepoint than ISO 8859-15. |
Vendor (Microsoft) |
CP1252 |
WE8MSWIN1252 |
CP1252 |
|
ISO 8859-2 |
Central/Eastern European Latin-2. Contains characters that are required for Central European languages, including Czech, Hungarian, and Polish. Does not include the euro symbol. |
ISO |
LATIN2 or ISO_8859-2 |
EE8ISO8859P2 |
CP28592 |
|
ISO 8859-15 |
Western European extended Latin-9. Similar to ISO 8859-1, but contains the euro symbol, oe ligature, and several characters that are required for Icelandic. |
ISO |
LATIN9 or ISO_8859-15 |
WE8ISO8859P15 |
CP28605 |
|
Most common Japanese character set. Defines thousands of characters for writing Japanese. |
Country (Japan) |
SJIS |
JA16SJIS |
CP932 |
|
|
IBM CCSID 37 |
IBM Coded Character Set ID 37. Western European Multilingual EBCDIC-based character set. |
Vendor (IBM) |
EBCDIC |
WE8EBCDIC37 |
CP1140 |
Some of these character sets, such as ISO 8859-1 and IBM CCSID 37, require only one byte to represent each character. For example, in ISO 8859-1, the hexadecimal number 61 represents the lowercase Latin letter a. However, larger character sets, such as Shift-JIS, may require more than one byte to represent each character.
The Unicode StandardThe most important consideration when dealing with character sets across a system is ensuring that all characters that you plan to represent within the PeopleSoft system exist in the character set that is used by each component of the system.
For example, if you plan to maintain Japanese characters in employee names, you must ensure that:
Character sets that are used by the database system include Japanese characters.
Each external system feeding into or out of the PeopleSoft system expects data in a character set that includes Japanese characters.
Workstations and printers are installed with fonts that include those characters.
For example, the Japanese Shift-JIS character set contains Japanese and many US-ASCII characters; it is sufficient for encoding both English data and the primary characters that are required in Japanese. However, it does not include the accented Latin characters that are needed for French and German, so it is not a suitable character set for implementations that encompass Western European countries.
Given the sample list of common character sets in the previous table and the number of languages that are required by a typical global PeopleSoft implementation, selecting a character set can be daunting, especially when you are planning to support a large list of languages.
To simplify this type of situation, an industry consortium of vendors devised a universal character set: the Unicode standard. This internationally recognized character set encodes every character that is required to write virtually every written language. The repertoire of characters is jointly maintained by the Unicode Consortium and ISO, and it is synchronized with ISO standard 10646: Universal Multiple-Octet Coded Character Set (UCS).
The PeopleSoft system uses Unicode throughout PeopleTools to simplify character handling. The PeopleSoft system allows the use of Unicode within PeopleSoft databases to enable you to maintain a single database with characters from virtually any language.
Unicode provides space for more than one million characters. To manage such a large repertoire of characters, Unicode defines 16 planes. Each plane contains 65,533 character positions. Plane 0, known as the Basic Multilingual Plane (BMP), is generally sufficient for everyday business use. The other planes are intended to encode extended or rarely used ideographic characters (such as Japanese, Chinese, and Korean ideographs), archaic scripts, and other rarely used characters, such as braille and advanced mathematical symbols.
Note. PeopleTools 8.4 supports the use of characters from the BMP only, otherwise known as plane 0. Supplementary characters are not supported in PeopleTools 8.4.
Based on the concept of 16 planes, each Unicode character has a unique, four-byte code. Using four bytes of storage per character may seem wasteful, especially considering that most applications today use a small collection of characters and that the vast majority of characters in business applications are from the BMP. Therefore, several different encoding forms for Unicode characters have been standardized and adopted by vendors who are implementing the standard.
Four encodings of Unicode are widely used. All of them are fully compatible with each other and share the same repertoire of characters. They differ, however, in how each character is represented at the byte level. These encodings are:
Universal Transformation Form - 32-bit (UTF-32).
Universal Transformation Form - 16-bit (UTF-16).
Universal Transformation Form - 8-bit (UTF-8).
Universal Character Set - 2-byte (UCS-2).
The PeopleSoft system currently supports UCS-2 and UTF-8 encodings; however, following are brief overviews of all four encodings.
Note. The PeopleSoft system supports only UTF-8 and several Asian character sets for outgoing email messages from PeopleTools application servers.
The following table summarizes the four Unicode encodings and their uses in the PeopleSoft system:
|
Unicode Encoding |
Minimum Bytes per Character |
Maximum Bytes per Character |
PeopleSoft System Usage |
|
4 |
4 |
None. |
|
|
2 |
4 |
None. |
|
|
1 |
4 |
PeopleSoft Pure Internet Architecture HTML pages, inbound and outbound XML, and Oracle databases. |
|
|
2 |
2 |
In-memory Microsoft Windows client; application server; Microsoft SQL Server and IBM DB2 UDB for Linux, Unix, and Microsoft Windows databases Unicode databases. |
This section includes Unicode encoding examples for the following characters:
|
a |
Latin small letter a. |
|
ñ |
Latin small letter n. |
|
|
Hiragana letter ka. |
The following table shows examples of these characters in each of the Unicode encodings:
|
Unicode Encoding |
Latin Small Letter a |
Latin Small Letter n with Tilde |
Hiragana Letter ka |
|
UTF-32 |
0x00000061 |
0x000000f1 |
0x0000304b |
|
UTF-16 |
0x0061 |
0x00f1 |
0x304b |
|
UTF-8 |
0x61 |
0xc3b1 |
0xe3818b |
|
UCS-2 |
0x0061 |
0x00f1 |
0x304b |
See Also
The Unicode Standard Version 3.0, The Unicode Consortium, Reading, MA, USA, Addison-Wesley Developers Press, 2000. ISBN 0-201-61633-5
http://www.unicode.org/unicode/uni2book/u2.html
Selecting Email Character Sets
Non-Unicode Character SetsAlthough much of the PeopleSoft system runs by using Unicode, you can configure several components with a non-Unicode character set. When making these choices, you should understand the types of character sets other than Unicode that exist.
This section discusses:
SBCSs.
DBCSs.
Note. For the sake of terminology, some systems, such as Microsoft Windows, refer to two types of character sets: Unicode and ANSI. ANSI, in this context, refers to the American National Standards Institute, which maintains equivalent standards for many national and international standard character sets. In the context of this book, ANSI character sets refer to non-Unicode character sets, which can be any international, national, or vendor standard character set, such as those that are discussed at the beginning of this chapter.
Most character sets use one byte to represent each character and are therefore known as SBCSs. These character sets are relatively simple and can represent up to 255 unique characters. Examples of SBCSs are ISO 8859-1 (Latin1), ISO 8859-2 (Latin2), Microsoft CP1252 (similar to Latin1, but vendor specific), and IBM CCSID 37.
DBCSs use one or two bytes to represent each character and are typically used for writing ideographic scripts, such as Japanese, Chinese, and Korean. Most DBCSs allow a mix of one-byte and two-byte characters, so you cannot assume an even-string byte length.
The PeopleSoft system supports two types of DBCS:
Nonshifting
Shifting
The difference between these types of DBCS is in the way in which the system determines whether a particular byte represents one character or is part of a two-byte character.
Character Sets in the PeopleSoft Pure Internet ArchitecturePeopleSoft installations include multiple components, each of which must handle differing character sets.
This diagram illustrates the PeopleSoft Unicode architecture:
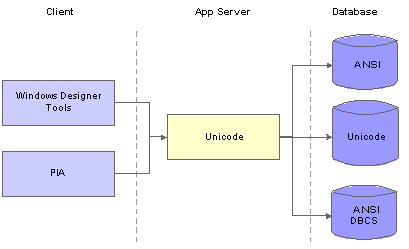
PeopleSoft Unicode architecture
PeopleSoft clients and application servers use Unicode exclusively and do not rely on other character sets to represent and process data. However, depending on your environment, not all system components support Unicode-encoded data, so you may not be able to run all parts of your system in Unicode. Therefore, PeopleTools enables you to configure these system components to use other character sets:
Not all database platforms support Unicode data storage. Even when Unicode storage is available, not all PeopleSoft implementations require the flexibility in language choices that are available with Unicode, so you can use a non-Unicode encoding for the database.
The character set that is used for PeopleSoft COBOL processing must match the character set of the database. If you created a Unicode database for the PeopleSoft implementation, you must also run COBOL in Unicode.
All file operations in PeopleTools, including file layout objects, trace and log files, and file operations from SQRs can be performed in Unicode or any supported non-Unicode character set. This is useful in situations in which you must interface with an external system that does not support Unicode.
Third-party products that are non-Unicode compliant.
Some third-party products that are supported by PeopleTools do not yet support Unicode. In this case, PeopleTools converts application data to a specific, non-Unicode character set before communicating with these tools. Some of the products that do not yet support Unicode data are Hyperion Essbase and Cognos PowerPlay.
When Unicode is not used for any of these types of operations or data storage, the PeopleSoft system transparently handles the conversion from Unicode to a non-Unicode character set. The non-Unicode character set that is used depends on several settings, which are discussed in detail later in this chapter.
The following table lists the character sets that the PeopleSoft system supports and the names by which they may be referred to in PeopleSoft applications. Use these character set names:
In PeopleCode programs for manipulating file layout objects.
In the Unix/Linux application server configuration to determine the default, non-Unicode character set for log files, trace files, and operating system interfaces.
When creating your database.
A limited number of the character sets in this table are supported as database character sets. Refer to your hardware and software requirements guide for details about the character sets that are supported for your database platform.
This PeopleBook also contains information about supported character set encodings for SQR for PeopleSoft globalization.
See SQR for PeopleSoft-Supported Character Set Encodings.
See Enterprise PeopleTools 8.49 Hardware and Software Requirements Guide.
|
Description and Comments |
Character Set Type |
|
|
Current ANSI-based code page. Not really a character set, but causes the system to use the default non-Unicode character set of the host operating system. With Microsoft Windows NT, the ANSI codepage is dependent on the language version of the Microsoft Windows operating system. For example, Japanese Windows NT uses CP932 as its ANSI codepage. English Windows NT uses CP1252 as its ANSI codepage. Microsoft Windows 2000 and XP enable the system administrator to select the ANSI codepage independently of the language release of Microsoft Windows. |
SBCS or DBCS, depending on the host operating system. |
|
|
ASCII |
7–bit US-ASCII |
SBCS |
|
Big5 |
Big5 (Traditional Chinese) |
Nonshifting DBCS |
|
CCSID1027 |
IBM EBCDIC 1027 (Japanese-Latin) |
SBCS |
|
CCSID1047 |
IBM EBCDIC 1047 (Latin1) |
SBCS |
|
CCSID290 |
IBM EBCDIC 290 (Katakana) |
SBCS |
|
CCSID300 |
IBM EBCDIC 300 (Kanji) |
Nonshifting DBCS |
|
CCSID930 |
IBM EBCDIC 930 (Kana-Kanji) |
Shifting DBCS |
|
CCSID935 |
IBM EBCDIC 935 (Simplified Chinese) |
Shifting DBCS |
|
CCSID937 |
IBM EBCDIC 937 (Traditional Chinese) |
Shifting DBCS |
|
CCSID939 |
IBM EBCDIC 939 (Latin-Kanji) |
Shifting DBCS |
|
CCSID942 |
IBM EBCDIC 942 (Japanese PC) |
Nonshifting DBCS |
|
CP1026 |
Windows 1026 (EBCDIC) |
SBCS |
|
CP1250 |
Windows 1250 (Eastern Europe) |
SBCS |
|
CP1251 |
Windows 1251 (Cyrillic) |
SBCS |
|
CP1252 |
Windows 1252 (Western Europe) |
SBCS |
|
CP1253 |
Windows 1253 (Greek) |
SBCS |
|
CP1254 |
Windows 1254 (Turkish) |
SBCS |
|
CP1255 |
Windows 1255 (Hebrew) |
SBCS |
|
CP1256 |
Windows 1256 (Arabic) |
SBCS |
|
CP1257 |
Windows 1257 (Baltic) |
SBCS |
|
CP1258 |
Windows 1258 (Vietnamese) |
SBCS |
|
CP1361 |
Windows 1361 (Korean Johab) |
SBCS |
|
CP437 |
MS-DOS 437 (US) |
SBCS |
|
CP500 |
Windows 500 (EBCDIC 500V1) |
SBCS |
|
CP708 |
Windows 708 (Arabic - ASMO708) |
SBCS |
|
CP720 |
Windows 720 (Arabic - ASMO) |
SBCS |
|
CP737 |
Windows 737 (Greek - 437G) |
SBCS |
|
CP775 |
Windows 775 (Baltic) |
SBCS |
|
CP850 |
MS-DOS 850 (Western Europe) |
SBCS |
|
CP852 |
MS-DOS 852 (Eastern Europe) |
SBCS |
|
CP855 |
MS-DOS 855 (IBM Cyrillic) |
SBCS |
|
CP857 |
MS-DOS 857 (IBM Turkish) |
SBCS |
|
CP860 |
MS-DOS 860 (IBM Portuguese) |
SBCS |
|
CP861 |
MS-DOS 861 (Icelandic) |
SBCS |
|
CP862 |
MS-DOS 862 (Hebrew) |
SBCS |
|
CP863 |
MS-DOS 863 (Canadian French) |
SBCS |
|
CP864 |
MS-DOS 864 (Arabic) |
SBCS |
|
CP865 |
MS-DOS 865 (Nordic) |
SBCS |
|
CP866 |
MS-DOS 866 (Russian) |
SBCS |
|
CP869 |
MS-DOS 869 (Modern Greek) |
SBCS |
|
CP870 |
Windows 870 |
SBCS |
|
CP874 |
Windows 874 (Thai) |
SBCS |
|
CP875 |
Windows 875 (EBCDIC) |
SBCS |
|
CP932 |
Windows 932 (Japanese) |
Nonshifting DBCS |
|
CP936 |
Windows 936 (Simplified Chinese) |
Nonshifting DBCS |
|
CP949 |
Windows 949 (Korean) |
Nonshifting DBCS |
|
CP950 |
Windows 950 (Traditional Chinese) |
Nonshifting DBCS |
|
EBCDIC |
IBM EBCDIC CCSID37 (USA) |
SBCS |
|
EUC-JP |
Extended UNIX code (Japanese) |
Nonshifting DBCS |
|
EUC-KR |
Extended UNIX code (Korean) |
Nonshifting DBCS |
|
EUC-TW |
Extended UNIX code (Taiwan) |
Nonshifting DBCS |
|
EUC-TW-1986 |
Extended UNIX code (TW-1986) |
Nonshifting DBCS |
|
GB12345 |
GB 2312 (Simplified Chinese) |
Nonshifting DBCS |
|
GB18030 |
GB18030 (Simplified Chinese) |
Nonshifting DBCS |
|
GB2312 |
GB 2312 (Simplified Chinese) |
Nonshifting DBCS |
|
HKSCS |
Hong Kong Supplementary Character Set |
Nonshifting DBCS |
|
ISO-2022-JP |
ISO-2022-JP Japanese |
Shifting DBCS |
|
ISO-2022-KR |
ISO-2022-JP Korean |
Shifting DBCS |
|
ISO_8859-1 |
ISO 8859-1 (Latin1) |
SBCS |
|
ISO_8859-10 |
ISO 8859-10 (Latin6) |
SBCS |
|
ISO_8859-11 |
ISO 8859-11 (Thai) |
SBCS |
|
ISO_8859-14 |
ISO 8859-14 (Latin8) |
SBCS |
|
ISO_8859-15 |
ISO 8859-15 (Latin9/Latin0) |
SBCS |
|
ISO_8859-2 |
ISO 8859-2 (Latin2) |
SBCS |
|
ISO_8859-3 |
ISO 8859-3 (Latin3) |
SBCS |
|
ISO_8859-4 |
ISO 8859-4 (Latin4) |
SBCS |
|
ISO_8859-5 |
ISO 8859-5 (Cyrillic) |
SBCS |
|
ISO_8859-6 |
ISO 8859-6 (Arabic) |
SBCS |
|
ISO_8859-7 |
ISO 8859-7 (Greek) |
SBCS |
|
ISO_8859-8 |
ISO 8859-8 (Hebrew) |
SBCS |
|
ISO_8859-9 |
ISO 8859-9 (Latin5) |
SBCS |
|
JIS_X0201 |
Japanese Half-width Katakana |
Nonshifting DBCS |
|
JIS_X_0208 |
Japanese Kanji |
Nonshifting DBCS |
|
Java |
Java (Unicode encoding) |
Unicode |
|
Johab |
Johab (Korean) |
Nonshifting DBCS |
|
Shift_JIS |
Shift-JIS (Japanese) |
Nonshifting DBCS |
|
UCS2 |
Unicode UCS-2 |
Unicode |
|
UTF7 |
Unicode UTF-7. (An outdated Unicode 7-bit clean transformation that is sometimes used for email that must pass through gateways that do not support 8-bit characters.) |
Unicode |
|
UTF8 |
Unicode UTF-8 |
Unicode |
See Also
For more information and code charts for Microsoft codepages, visit http://www.microsoft.com/globaldev/reference/cphome.asp
For more information and code charts for Unicode, visit http://www.unicode.org
Selecting Character Sets
This section discuses how to:
Select database character sets.
Select application server character sets.
Select and manage client workstation character sets.
Select email character sets.
See Also
Selecting Database Character SetsThe primary character set decision that you must make when installing a PeopleSoft implementation is which character set to use for the database system. Ideally, all databases are encoded in Unicode; however, in some cases Unicode requires several bytes to represent each character when only one byte may be required in a non-Unicode character set. Therefore, the PeopleSoft system enables you to use certain non-Unicode character sets for the database.
By using a Unicode encoded database, you can maintain a single database with data in any combination of languages. A single PeopleSoft application server can serve multiple users connecting to the mixed-language database, regardless of the language or character set of those users’ client machines. The only restriction on a user’s ability to access mixed-language data is the capability of the user’s client workstation to interpret, display, and accept keyboard entry of the characters from the various languages.
Most language or region-specific non-Unicode character sets provide sufficient characters for only a few languages. If you create a non-Unicode database, you must ensure that all of the characters for all of the languages that you plan on using can be represented in the character set that you choose.
Depending on the data that you store and how the database stores Unicode characters, a Unicode database can be significantly larger than a non-Unicode database. However, only the storage of character data is affected; the space that is required for non-character data, such as numbers and dates (which are stored by the database system as numbers), is not affected.
Depending on the database platform, you can use one of the four character set types (SBCS, nonshifting DBCS, shifting DBCS, or Unicode) when creating the database. However, the number of characters that you can store in each column is affected greatly by the type of character set that you choose for the database encoding.
See Also
Enterprise PeopleTools 8.49 Hardware and Software Requirements Guide
Enterprise PeopleTools 8.49 Installation Guide for Your Database Platform
Your operating system and database guides
Selecting Application Server Character SetsAll data that is stored in memory and processed by the PeopleTools application server is held in Unicode. However, the application server allows files on the server (created through PeopleCode file layout objects) and log and trace files to be Unicode or non-Unicode. Although the PeopleSoft application server uses Unicode internally for all data processing, it can create these files in Unicode or in a non-Unicode character set.
Each PeopleSoft application server is configured with a default non-Unicode character set. If a file operation must create a non-Unicode file, this character set is used, unless another character set is explicitly specified in the file operation. For example, if you create a file layout object to write a non-Unicode file, but you don’t specify in which character set the file should be created, the default non-Unicode character set of the application server is used.
Microsoft Windows 2000 and XP enable you to change the default character set of the system, although as installed, the default character set matches the default locale of the Microsoft Windows 2000 or XP installation. To change the system default locale (and therefore the character set), on Microsoft Windows 2000 servers, use the Control Panel’s Regional Options menu. In the Language settings for the system section, click the Set Default button.
When running on Unix/Linux, the PeopleSoft application server enables you to specify the default non-Unicode character set in the application server’s configuration file, which you select by using the PSADMIN tool. Any valid PeopleSoft character set with a character set type of SBCS or nonshifting DBCS is a valid default non-Unicode character set for PeopleSoft application servers that run on Unix/Linux.
See Also
Character Sets in the PeopleSoft Pure Internet Architecture
Selecting and Managing Client Workstation Character Sets
You must consider the client components of PeopleTools when you are planning your language strategy. The requirements for language support on client workstations are different, depending on whether you are using the PeopleSoft Pure Internet Architecture or the PeopleTools development tools for Microsoft Windows.
This section discusses:
Character sets and fonts in the PeopleSoft Pure Internet Architecture.
Fonts and the Microsoft Windows client.
Input methods.
Character Sets and Fonts in the PeopleSoft Pure Internet Architecture
The PeopleSoft Pure Internet Architecture serves all HTML pages in the UTF-8 encoding of Unicode. This encoding is recognized automatically by the web browser, because the encoding of the page is announced in the HTTP header when the browser communicates with the web server. Most modern browsers can support the use of UTF-8 encoded HTML pages, including all browsers that are supported by PeopleTools.
However, the browser needs other components to correctly display and enter the vast array of characters that are available in Unicode. Specifically, you need appropriate fonts to display the various scripts in which you expect data to be maintained, and you may need alternative keyboard layouts or, in the case of ideographic scripts such as Chinese, Japanese, and Korean, you need input method editors (IMEs) to convert sequences of keystrokes into ideographs. The requirement for alternate keyboard and IMEs is the same for both the PeopleSoft Pure Internet Architecture and the Microsoft Windows client.
Not all fonts contain a full repertoire of Unicode characters, because many fonts are tailored to address a specific list of languages and contain only the glyphs that are required by those languages. If you try to view Unicode data with a font that does not contain the appropriate characters for the displayed language, you will most likely see square boxes in place of the appropriate characters. The data has not been corrupted; there is just no glyph available in the current font for the character that the system is trying to display. For this reason, you may need to license or configure several fonts for a global PeopleSoft system.
The PeopleSoft Pure Internet Architecture includes a set of style sheets, defined with PeopleSoft Application Designer, that determine the font that is used to display HTML pages. In some cases, the application data may contain characters that are not present in this font and that require a different font.
You may need to obtain and configure fonts that contain the characters for the languages that you are planning to use, if your workstations are not already configured with these fonts. Obtain fonts from the following sources:
Many Microsoft Windows and other operating system applications are packaged with Unicode fonts containing glyphs covering a large range of languages.
Microsoft Office 2000 is packaged with several fonts containing a large portion of the characters in Unicode, including the Microsoft Sans Serif font. Use these fonts in the PeopleSoft Pure Internet Architecture by specifying them in the PeopleSoft Application Designer style sheet definitions or by following the browser-specific instructions in this section.
Several public domain fonts exist that contain a large character repertoire for use in web browsers. For a list of such fonts, see http://www.hclrss.demon.co.uk/unicode/fonts.html.
Several font foundries license fonts for individual or corporate use.
Some of these foundries include Agfa Monotype, Bitstream, and Tiro Typeworks.
Depending on your browser, you can also download fonts from your browser’s manufacturer.
Fonts and the Microsoft Windows Client
The Microsoft Windows client enables you to specify the font that is used for all graphical components in PeopleSoft Application Designer, the Microsoft Windows client panel processor, and all other PeopleTools modules for Microsoft Windows. Three separate areas enable you to specify a font:
Configuration Manager font setting (Display tab)
This setting affects the font that is used by all of the designer components of PeopleTools, including all of the text that is contained in the Microsoft Windows resource files
Changing this font setting may be necessary if your workstation’s default locale does not contain the characters that are used for the language that you are attempting to display or maintain. For example, if you are attempting to view Japanese characters on an English Microsoft Windows workstation, you can change the PeopleSoft Configuration Manager font setting to select a font that contains the characters for the language that you are trying to display.
Several fonts that are shipped with Microsoft Windows 2000 and Microsoft Office 2000, including Arial Unicode MS and Microsoft Sans Serif, contain a large number of glyphs covering most of the languages that are supported by Unicode. Microsoft Windows 2000 and Microsoft Windows XP can also be configured with fonts for most worldwide languages by selecting the required languages under the Regional Settings Control Panel menu.
The PeopleCode editor in PeopleSoft Application Designer also enables you to select a font for character display in the editor’s window itself. This is useful if the PeopleCode programs that you are working on contain Unicode characters. To set the font in PeopleSoft Application Designer, select Tools, Options and then select the PeopleCode tab.
If users will enter foreign language data by using PeopleSoft Pure Internet Architecture or the Microsoft Windows client, you must ensure that an appropriate keyboard layout or input method editor is installed on the workstation.
Most alphabetic languages can be typed by using a relatively simple keyboard layout. Several specialized keyboard layouts exist for most languages; configure these keyboard layouts through your operating system. For example, a Spanish keyboard layout contains keys for the n-tilde character (ñ) and several other accented characters.
There are several ways of entering these characters by using a nonlocalized keyboard. Your operating system manual can help you use specialized keyboard layouts, such as the English International layout, which enables you to enter accented characters by using two keystrokes. The Microsoft web site contains information about keyboards that are supported by Microsoft Windows and instructions for installing and configuring Windows keyboard layouts.
Ideographic languages, such as Chinese, Japanese, and Korean, require the use of a front-end processor to intercept multiple keyboard strokes and transform them into an ideographic character. These are known as IMEs, and they must be installed on each workstation where you plan to enter the ideographic languages.
Most localized versions of operating systems for these languages come preconfigured with IMEs that are appropriate for the language that is supported by the operating system. But on systems where the default locale is not Chinese, Japanese, or Korean, you may need to configure or license an IME from a third-party vendor. The PeopleSoft Pure Internet Architecture supports any IME that is supported by your browser. The designer tools in Microsoft Windows support all standard Microsoft IMEs.
Selecting Email Character SetsThe PeopleSoft system supports UTF-8 for outgoing Simple Mail Transfer Protocol (SMTP) email messages from PeopleTools application servers. In addition, because many email products in Asian markets support only traditional character sets, the PeopleSoft system supports several additional character sets for outgoing email.
PeopleSoft application servers support the following character sets for outgoing email:
UTF-8 (default).
ISO-2022-KR, EUC-KR (for Korean).
GBK, Big5 (for Chinese).
Specifying Email Character Sets
You specify an email character set in the SMTPCharacterSet parameter in the application server configuration file, psappsrv.cfg. By default, the SMTPCharacterSet parameter is set to UTF-8.
Note. You should specify a value for the SMTPCharacterSet. If you do not specify a value for the parameter, email is sent as-is, with no encoding. Leave the parameter set to the default value of UTF-8 if you are not certain about which value to use.
For example, to use ISO-2022-JP encoding for outgoing SMTP mail, in the psappsrv.cfg file, set the SMTPCharacterSet parameter to ISO-2022-JP, as shown in the following example:

SMTP settings
Writing Custom SMTP Encoding Modules
You can also write your own SMTPEncodingDLL modules, if necessary.
Validating Field Length
This section provides overviews of PeopleSoft Application Designer field length semantics and field length checking for non-Unicode databases and discusses how to enable or disable data field length checking.
Understanding Application Designer Field Length SemanticsThe database character set determines the way that PeopleTools interprets the column length that is defined in PeopleSoft Application Designer.
If you create a Unicode database, the field length, as shown in PeopleSoft Application Designer, indicates the maximum number of Unicode BMP characters that are permitted in the field, regardless of the Unicode encoding that is used by the database. Some database platforms, such as Oracle with byte semantics, use byte lengths to measure column sizes when operating in a Unicode database, while others use character lengths.
When the database uses byte-sized column lengths, the PeopleSoft system sizes the database columns based on the worst-case ratio between bytes and characters in the Unicode encoding that is used by your database. For example, the UTF-8 character set is used by Oracle with byte semantics; therefore, the worst-case character-to-byte ratio, when running against an Oracle Unicode database, is 1:3, so column size is tripled when creating a Unicode database on Oracle. A field that is defined in PeopleSoft Application Designer as a CHAR(10) is created on an Oracle Unicode database with a type of VARCHAR2(30). This tripling of the maximum column size does not affect the actual size of the database, because variable length character fields do not reserve space in the database.
Other database platforms use character-based column lengths whose sizes represent the maximum number of Unicode characters instead of bytes that may be stored. Examples of this implementation are the NCHAR data type in Microsoft SQL Server and the GRAPHIC data type in DB2 UDB for Linux, Unix, and Microsoft Windows.
If you create a non-Unicode database, the field length in PeopleSoft Application Designer represents the number of bytes that are permitted in the field, based on the character set that you used to create the database. Therefore, a PeopleSoft Unicode database enables you significantly more space for character data within the database when dealing with ideographic languages, such as Japanese, that require more than one byte storage per character.
The following tables show some of the possible database encodings for database platforms that the PeopleSoft system supports in Unicode and DBCS and their effects on database column sizes.
For Oracle with byte semantics (PeopleTools 8.48 or higher):
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Unicode (UTF-8) |
VARCHAR2(30) |
10 |
|
Any SBCS |
VARCHAR2(10) |
10 |
|
Shift-JIS (JA16SJIS) |
VARCHAR2(10) |
5 |
For Oracle with character semantics:
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Unicode (UTF-8) |
VARCHAR2(20) |
10 |
|
Any SBCS |
VARCHAR2(10) |
10 |
|
Shift-JIS (JA16SJIS) |
VARCHAR2(10) |
10 |
For Microsoft SQL Server with Varchar (PeopleTools 8.48 or higher):
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Unicode (UCS-2) |
NVARCHAR(10) |
10 |
|
Any SBCS |
VARCHAR(10) |
10 |
|
Shift-JIS (CP932) |
VARCHAR(10) |
5 |
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Unicode (UCS-2) |
NCHAR(10) |
10 |
|
Any SBCS |
CHAR(10) |
10 |
|
Shift-JIS (CP932) |
CHAR(10) |
5 |
For DB2 UDB for OS/390 and z/OS:
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Any SBCS |
CHAR(10) |
10 |
|
Shifting DBCS (CCSID 930/939) |
CHAR(10) |
4 (4 x 2 byte characters, plus shift-in & shift-out bytes) |
For all others:
|
Database Character Set |
Database Representation of a Character Field with a Length of 10 in PeopleSoft Application Designer |
Number of Characters (Worst Case) Allowed in a Character Field with a Length of 10 in PeopleSoft Application Designer |
|
Any SBCS |
CHAR(10) |
10 |
Understanding Field Length Checking for Non-Unicode DatabasesThe maximum number of characters that are permitted in a PeopleSoft field varies, depending on the character set of the database. Because all components of PeopleTools use Unicode for internal storage, by default, field length checking occurs in terms of Unicode character counts. This calculation is appropriate for Unicode databases and for any SBCS databases.
However, if you are using a non-Unicode DBCS, special length checking must occur each time you move off a field to ensure that the string that you entered fits in the database column when the string is converted to the database’s character set.
For graphically sizing page fields, PeopleTools uses the Unicode length of the field as defined in PeopleSoft Application Designer. For example, if a field is defined in PeopleSoft Application Designer as a 10-character field, page fields in both the PeopleSoft Pure Internet Architecture and the PeopleTools clients for Microsoft Windows allow 10 characters to be displayed unless manually resized by the developer.
However, if the database is encoded in a non-Unicode DBCS character set, such as Japanese Shift-JIS or IBM CCSID 930/939, special length validation must occur because the database column size is created relative to a byte count, not to a character count as is used by the simple field length validation.
For example, if a user enters 10 Japanese characters into a field that is defined as CHAR(10) in PeopleSoft Application Designer, this string needs 20 bytes of storage in a nonshifting DBCS character set and 22 bytes of storage in a shifting character set. This 10-character input would fail insertion in both of these databases.
To address this issue, the page processor checks the Data Field Length Checking option on the PeopleTools Options page and performs character-set specific length validation against the contents of each field when the field is validated. Typically length validation occurs when the field’s FieldChange PeopleCode event fires, so the actual time of validation may differ, depending on whether your page uses deferred mode processing.
Enabling or Disabling Data Field Length CheckingTo enable or disable data field length checking:
Select PeopleTools, Utilities, Administration, PeopleTools Options.
The PeopleTools Options page appears.
From the Data Field Length Checking drop-down list box, select a value based on the character set that you are using for the database:
|
Others |
Select if you are using a Unicode encoded database or a non-Unicode SBCS database. This option prevents special field length checking, which is not required by these types of databases. |
|
Select if you are running a Japanese database on the DB2 UDB for Linux, Unix, and Microsoft Windows platform. This options enables field length checking based on a shifting DBCS. |
|
|
MBCS |
Select if you are running a non-Unicode Japanese database on any other platform. This option enables field length checking based on a nonshifting DBCS. |
Note. The non-Unicode DBCS settings are specifically oriented to Japanese language installations, because Japanese is the only language that the PeopleSoft system supports in a non-Unicode DBCS encoding. All languages other than Western European languages and Japanese are supported by the PeopleSoft system only when using Unicode encoded databases.
Save the page.
Handling International Characters in PeopleToolsPeopleTools contains several features that enable you to manipulate character data based on the language, script, or type of character being processed. Some field formats, such as the Name format, are dependent on the language of the data being maintained. Several PeopleCode functions enable you to manipulate language-dependent characters.
This section discusses standard name formats for Chinese, Japanese, and Korean characters.
Standard Name Formats for Chinese, Japanese, and Korean CharactersThe PeopleSoft standard name format is:
[lastname] [suffix],[prefix] [firstname] [middle name/initial]
However, if the name contains any of the following types of characters, you must separate the first and last names by a space instead of a comma:
Chinese, Japanese, and Korean Unified Ideographs (Chinese Hanzi, Japanese Kanji, and Korean Hanja).
Japanese half-width or full-width Katakana.
Japanese Hiragana.
Korean Hangul.
The following example shows the PeopleSoft standard name format when any one of the previous types of characters appears:
[lastname] [suffix] [prefix] [firstname] [middle name/initial]
This format allows for Chinese, Japanese, and Korean names, which are traditionally separated by spaces, and which would appear incorrectly if separated by a comma.
Detecting and Converting CharactersPeopleTools also provides PeopleCode string functions that recognize and convert between different characters within the Japanese character set. This enables you to detect, convert, and enforce the types of characters that you can enter in any PeopleSoft field. The PeopleSoft system uses these functions in the development of Alternate Character Architecture in some PeopleSoft applications. Alternate Character Architecture is used in several PeopleSoft applications to provide a feature that enables the entry of, and enforces the characters contained in, Japanese phonetic spellings (Furigana) by using the Hiragana or Katakana scripts.
The following PeopleCode string functions recognize and convert between different characters within the Japanese character set:
CharType
ContainsCharType
ContainsOnlyCharType
ConvertChar
See Also