
 Understanding Data Cubes
Understanding Data CubesThis chapter provides overviews of data cubes and the relationship between field definition attributes and data cube formats and discusses how to:
Create input data cubes.
Create calculation data cubes.
Create association data cubes.
Create virtual data cubes.
Define data cube properties.
Audit data cubes at design time.
Understanding Data CubesThis section provides overviews of:
Definition of a data cube.
Input data cubes.
Calculation data cubes.
Association data cubes.
Virtual data cubes.
Definition of a Data CubeA data cube is a container for one kind of data that you use in cube collections.
You can place the same data cube in more than one cube collection. For example, you can place the EMPLOYEE_EXPENSE data cube in both an EMPLOYEE_ANALYSIS cube collection and an INCOME_STATEMENT cube collection. To populate the data cubes with data from the database, you map fields to the data cubes within the cube collection's properties.
See Mapping Data Cubes and Dimensions to Fields.
Within PeopleSoft Pure Internet Architecture pages with analytic grids, end users view cube collections and drag and drop data cubes to view their relationships to other data cubes.
You create four different types of data cubes that you use within an analytic model:
Input data cubes.
Calculation data cubes.
Association data cubes.
Virtual data cubes.
The four types of data cubes are not mutually exclusive, but certain combinational restrictions apply. For example, consider that all calculation data cubes contain formulas, and association data cubes may or may not contain formulas. When an association data cube does contain a formula, it is considered to be a type of calculation data cube. Similarly, when an input data cube contains a formula, it is also considered to be a type of calculation data cube. Any of these data cubes may also be considered virtual data cubes if their values are not stored in the database.
This table lists each type of data cube and specifies whether the data cube can contain a formula, whether the data cube can lack a formula, whether the data cube can be virtual, and whether the data cube can be nonvirtual:
|
Data Cube Type |
Formula Allowed? |
No Formula Allowed? |
Can Be Virtual? |
Can Be Nonvirtual? |
|
Input |
Yes Note. When input data cubes contain formulas, they must use the INPUT built-in function. |
Yes |
No |
Yes |
|
Calculation |
Yes |
No |
Yes |
Yes |
|
Association |
Yes |
Yes |
Yes |
Yes |
|
Virtual |
Yes |
No |
Yes |
No |
Example: Working with Data Cubes and Dimensions
To be useful, a data cube must work with one or more dimensions. For example, suppose that you want to track the sales of multiple products in multiple regions. First, create an input data cube called SALES and dimensions called PRODUCTS and REGIONS. Next, attach the PRODUCTS dimension and REGIONS dimension to the SALES data cube.
Note. When a cube collection is mapped to either a Writable-only record or a record with the Readable and Writable attributes, all data cubes in the cube collection should share the same set of dimensions.
See Also
Input Data CubesInput data cubes receive their data from either the end user in the application or tables/views in the database. Input data cubes can exist in all types of cube collections, although they do not serve a purpose in intermediate/calculation cube collections. Use the INPUT built-in function to work with input cube data.
Note. Even though an input cube that uses either the INPUT built-in function is considered to be a type of calculation data cube, it would not serve a purpose in an intermediate/calculation cube collection.
See INPUT.
See Also
Calculation Data CubesCalculation data cubes contain formulas that calculate data based on the data of other cubes. Calculation data cubes can exist in all types of cube collections.
Note. Even though an input cube that uses either the INPUT built-in function is considered to be a type of calculation data cube, it would not serve a purpose in an intermediate/calculation cube collection.
See Also
Creating Calculation Data Cubes
Association Data CubesAn association data cube is a data cube that is formatted as a member of a dimension and has one or more attached dimensions. An association data cube associates two dimensions, enabling the end user to group members of one dimension into categories that are defined by the members of a different dimension. When an association data cube receives its values from dimension members, it can be considered to be a type of input data cube. When an association data cube receives its values from a calculation formula, it can be considered to be a type of calculation data cube.
Association data cubes can exist in all types of cube collections.
Example: Creating the DEPT_TO_REGION Association Data Cube
This example associates the DEPTID dimension with the REGION dimension. This table lists the members that are included in each dimension:
|
DEPTID Dimension Members Note. In the application, the end users group or categorize these members by categories that are defined by the members of the REGION dimension. |
REGION Dimension Members Note. In the application, the end users select members from this dimension to group members of the DEPTID dimension. |
|
AUS01 |
APAC |
|
AUS02 |
LATAM |
|
BRA01 |
NAMER |
|
CAN01 |
EUROP |
|
EUR01 |
NA |
|
GBR01 |
NA |
|
JAP01 |
NA |
|
JAP02 |
NA |
|
MEX01 |
NA |
|
USA01 |
NA |
|
USA02 |
NA |
This association enables the end user to group the members of the DEPTID dimension into categories that are defined by the members of the REGION dimension.
To create the DEPT_TO_REGION association data cube:
Create a new data cube named DEPT_TO_REGION.
Format the data cube as a member of the REGION dimension.
This dimension contains the categories that the end user will use to group the members of the DEPTID dimension. These members appear in the right-hand column of the data cube's data. The end user can select these members from a drop-down list box.
Attach the DEPTID dimension to the DEPT_TO_REGION association data cube.
This dimension contains the members that the end user will group or categorize. These members appear in the left-hand column of the data cube's data.
This example shows an association data cube and its drop-down list box in an analytic grid:
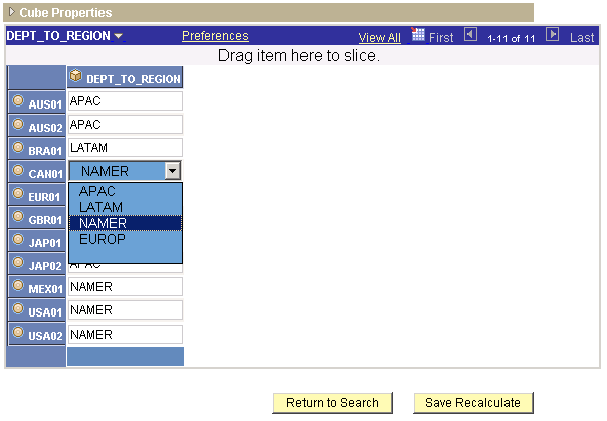
DEPT_TO_REGION association data cube in the Analytic Model Viewer
See Also
Creating Association Data Cubes
Virtual Data CubesA virtual data cube is a type of calculation data cube whose values are not saved to the database. Virtual data cubes can exist in intermediate/calculation and presentation cube collections.
This table describes the characteristics of virtual data cubes and the resulting benefits to the analytic model:
|
Characteristic |
Benefit |
|
Value data of virtual data cube is not stored in the database. |
Reduces:
|
|
The analytic calculation engine does not recalculate the virtual data cube unless the virtual data cube has nonvirtual dependents. |
Reduces recalculation time. |
|
The analytic calculation engine neither allocates memory nor calculates virtual data cubes until it receives a request for recalculation of the virtual data cube. |
Reduces memory consumption and recalculation time. |
See Defining General Data Cube Properties.
When an end user loads an analytic instance, the underlying analytic model's virtual data cubes do not contain data. However, as soon as the analytic calculation engine receives a request for a virtual cube's data, the analytic calculation engine calculates the entire cube and places the totals and all nonzero values in a temporary storage area. After this point—if the application requires the data—the analytic calculation engine retrieves the data from the temporary storage area.
Virtual cube data is recalculated for these circumstances:
The virtual data cube's data is displayed in an analytic grid.
The virtual data cube is used during a step of a recalculation.
The virtual data cube is accessed by a user function, even if the cube's data does not appear in the application.
An application uses a PeopleCode program to request data from the virtual data cube.
Note. Whenever a circumstance requires a recalculation of all the data in an analytic model (for example, when the application adds a member to a dimension), the temporary storage for all virtual data cubes is discarded. This storage is created again as needed.
Virtual data cubes have the following two restrictions. Otherwise, you can use virtual data cubes in the way you use nonvirtual data cubes.
Because a virtual data cube does not permanently store data, it must contain a formula to generate its data.
Note. Deleting the formula for a virtual data cube results in an invalid analytic model.
A virtual data cube cannot participate in recursive or circular systems because a virtual data cube's formula cannot refer to itself, either directly or indirectly.
This restriction applies because the first time a virtual cube's data is requested, the analytic calculation engine calculates and stores the data for the entire virtual data cube. In recursive or circular systems, the analytic calculation engine cannot calculate all of the data at the same time for any given data cube.
Note. If a virtual cube is part of a recursive or circular system, the analytic calculation engine generates an error value for all of the cube's values. Use the Recalculate function in the Analytic Calculation Engine classes to determine whether you violated this restriction. The Recalculate function returns a VIRTUAL error for the data cube cells that are affected.
PeopleSoft recommends that you create virtual data cubes when you expect the cubes to be large, sparse, and output-only, especially when a relatively small slice of the ordinary cubes is used in any given analytic instance ID. The analytic calculation engine takes a long time to recalculate nonvirtual cubes that are large, sparse, and output-only. When you make these cubes into virtual cubes, you eliminate them from the recalculation process and drastically reduce memory requirements. If an analytic instance uses only a small slice of the cube, the cube calculates on demand quickly and requires less memory because of the sparsity compression.
Virtual cubes are also useful for intermediate calculations that do not require permanent storage permanently, especially if these cubes would normally be large and sparse.
Note. You cannot use virtual cubes for intermediate calculations that are part of a recursive or circular system.
Note. Do not create virtual cubes out of large, dense cubes that are displayed frequently and take a long time to recalculate. Such virtual cubes cause delays when an application requests data. To be certain of recalculation time, PeopleSoft recommends you test whether using a virtual cube causes a significant delay in the generation of data.
See Understanding Circular Systems and Recursive Systems, Recalculate.
Intermediate virtual cubes can count as output-only cubes, as long as they do not have nonvirtual dependents. For example, you can create formulas such as the following for output-only virtual cubes:
This formula is for the SALARY_BY_EMPLOYEE data cube:
GROUPSUM(RCD JOB, SALARY, BUDGET_PERIOD, BUS_UNIT, EMPID, LEDGER, VERSION)
This formula is for the BENEFITS_BY_EMPLOYEE data cube:
GROUPSUM(RCD JOB, BENEFITS, BUDGET_PERIOD, BUS_UNIT, EMPID, LEDGER, VERSION)
This formula is for the SALARY_AND_BENEFITS_BY_EMPLOYEE data cube:
SALARY_BY_EMPLOYEE + BENEFITS_BY_EMPLOYEE
Even though SALARY_BY_EMPLOYEE and BENEFITS_BY_EMPLOYEE are used by another virtual cube, they are not recalculated by the analytic calculation engine if there are no nonvirtual dependents. For this reason, you must write the final formula for the SALARY_AND_BENEFITS_BY_EMPLOYEE data cube in this way:
GROUPSUM(RCD_JOB, SALARY, BUDGET_PERIOD, BUS_UNIT, EMPID, LEDGER, VERSION) + GROUPSUM(RCD JOB, Benefits, Budget Period, Bus Unit, EmpID, Ledger, Version)
See Also
Understanding the Relationship Between Field Definition Attributes and Data Cube FormatsBecause data cubes receive data from fields, it is important to correctly set both the attributes of field definitions and the formats of data cubes to ensure compatibility. The following table describes compatibilities between field definition attributes and data cube formats. Cells marked Yes indicate compatibility. Cells marked No indicate incompatibility. Cells marked Warn indicate potential compatibility and yield a warning during design time. During runtime, the analytic calculation engine generates an error if it determines that the mapping is not compatible.
|
Field Definition Attributes |
Data Cube Format: Number |
Data Cube Format: Date |
Data Cube Format: Member |
Data Cube Format: Text |
|
Char |
Warn |
Warn |
Yes |
Yes |
|
Number |
Yes |
No |
Yes |
Yes |
|
Signed Number |
Yes |
No |
Yes |
Yes |
|
Date |
No |
Yes |
Yes |
Yes |
|
Time |
No |
No |
No |
No |
|
Date Time |
No |
Warn Note. When a date-formatted data cube is mapped to a field with a Date Time attribute, time-specific data is truncated in the data cube data. |
Yes |
Yes |
|
Image |
No |
No |
No |
No |
|
Long Char |
No |
No |
No |
No |
See Also
Defining General Data Cube Properties
Creating Input Data CubesTo create an input data cube:
Select Part, New, Data Cube.
The Edit Part Name dialog box appears.
Enter the data cube name.
Click OK.
Note. Do not create formulas for input data cubes.
See Also
Creating Calculation Data CubesTo create a calculation data cube:
Select Part, New, Data Cube.
The Edit Part Name dialog box appears.
Enter the data cube name.
Click OK.
Create a formula for the calculation data cube.
See Also
Creating Association Data CubesTo create an association data cube:
Select Part, New, Data Cube.
The Edit Part Name dialog box appears.
Enter the data cube name.
Click OK..
Format the data cube as a member of a dimension.
This dimension contains the members that the end user will group or categorize. In the application, these members appear in the left-hand column of the data cube's data.
Attach a different dimension to the data cube.
This dimension contains the categories by which the end user will group the members of the X dimension. These members appear in the right-hand column of the data cube's data. The end user can select these members from a drop-down list box.
See Also
Creating Virtual Data CubesTo create a virtual data cube:
Select Part, New, Data Cube.
The Edit Part Name dialog box appears.
Enter the name of the data cube.
Click OK.
On the General tab of the data cube's properties, select Virtual Cube (doesn't store data).
See Also
Defining Data Cube Properties
This section discusses how to:
Define general data cube properties.
Select aggregate functions for attached dimensions.
Defining General Data Cube PropertiesSelect the data cube whose properties you want to define, and then select the General tab.
|
Data Cube |
Displays the name of the data cube. |
|
Number: Select to format the data cube's values as numbers. Date: Select to format the data cube's values as a date in the format YYYY-MM-DD. For example, 2004/03/18 for March 18, 2004. Note. Although the values are saved in the database using this date format, end users can use My Personalizations to select a different display format in PeopleSoft Pure Internet Architecture. See Defining Your User Personalizations. Member: Select to format the data cube's values as members of a specified dimension, as part of creating an association data cube. When you select Member, the Dimension drop-down list box appears. Select a dimension for which you want to format the data cube's values as members. For example, you can format a CUSTOMER_ID data cube as a member of the CUSTID dimension. Note. In the analytic grid, data cubes formatted as members should have a field type of Edit Box. Text: Select to format the data cube's values as text. This option is useful for entering names, addresses, and other textual data. |
|
|
Select to set the data cube as a virtual data cube. Clear to set the data cube as a nonvirtual data cube. See Virtual Data Cubes. Note. A virtual data cube must contain a formula. Selecting this option without entering and accepting a formula for a virtual data cube results in an invalid analytic model. |
|
|
Select to enable calculation of the data cube's aggregates. Note. If Calculate Aggregate is enabled for the data cube, the analytic calculation engine initially retrieves the aggregate data from the aggregate record when the analytic instance is loaded, but overwrites this data upon recalculation. If this check box is disabled, values from the aggregate record still load when the analytic instance is loaded; however, these values are not recalculated. Clear this check box to disable calculation of all of the data cube's aggregates, regardless of specified overrides. Note. Disabling aggregate calculation for data cubes disables all aggregate calculations, including the default sum aggregation. |
See Also
Understanding the Relationship Between Field Definition Attributes and Data Cube Formats
Selecting Aggregate Functions for Attached DimensionsSelect the data cube for which you want to select an aggregate function, and then select the Dimensions tab.
|
Displays the names of the dimensions that are attached to the data cube. |
|
|
Aggregate Function |
Select a cube dimension override user function to calculate the aggregates for the dimension as it is attached to the data cube. |
Auditing Data Cubes at Design TimeThis section provides overviews of causes and inputs and of effects and discusses how to:
Display causes and inputs.
Display effects.
Use the Causes and Effects tool.
Note. This section discusses auditing data cubes in design time. Use the Analytic Model Viewer to audit cube collections and data cubes in runtime.
See Viewing and Debugging Cube Collections.
Understanding Causes and InputsAny data cube that affects another data cube is a cause—or precedent—of that data cube. A data cube can be a direct cause or an indirect cause of another data cube. A direct cause is used in the data cube's formula. An indirect cause is not used in the formula, but it appears somewhere in the chain of formulas that ultimately affect the data cube.
For example, suppose the GROSS_MARGIN and NET_INCOME data cubes contain these formulas:
Formula for the GROSS_MARGIN data cube:
SALES - COST_OF_GOODS
Formula for the NET_INCOME data cube:
GROSS_MARGIN - TOTAL_EXPENSE
In this example, SALES is a direct cause of GROSS_MARGIN because it is used in GROSS_MARGIN's formula. SALES is an indirect cause of NET_INCOME because it affects GROSS_MARGIN, which in turn affects NET_INCOME.
You can display the causes of a data cube to view the assumptions behind a result or to find a formula that is not working properly.
Using the All Inputs option, you can also display all of the input data cubes that affect a data cube, either directly or indirectly.
See Displaying Causes and Inputs.
Understanding EffectsAny data cube that is affected by another data cube is an effect—or dependent—of that data cube. A data cube can be a direct effect or an indirect effect of another data cube. A direct effect uses the data cube in its formula. An indirect effect does not use the data cube in its formula, but it is part of the chain of calculations that are affected by the data cube.
Again, suppose the GROSS_MARGIN and NET_INCOME data cubes contain these formulas:
Formula for the GROSS_MARGIN data cube:
SALES - COST_OF_GOODS
Formula for the NET_INCOME data cube:
GROSS_MARGIN - TOTAL_EXPENSE
GROSS_MARGIN is a direct effect of SALES because it uses SALES in its formula. NET_INCOME is an indirect effect of SALES because it is affected by GROSS_MARGIN, which in turn is affected by SALES.
You can display either the direct or direct plus indirect effects of a data cube to view the consequences of a data cube's values.
See Displaying Effects.
Displaying Causes and InputsTo display the causes or inputs of a data cube:
Select a data cube whose causes or inputs you want to display.
To select several consecutive data cubes, hold down the Shift key and select the data cubes.
To select a series of nonconsecutive data cubes, hold down the Ctrl key and select the data cubes.
Select Tools, Analytic Model, Causes.
Select one of these options:
Direct Causes.
All Causes.
All Inputs.
When applicable, the Causes and Effects dialog box displays the causes or inputs of the data cube. You expand any of the data cubes in the dialog box to view their attached dimensions.
Note. The All Inputs option does not display the INPUT built-in function.
Click Close when you have finished viewing the causes or inputs.
Note. You can also display causes and inputs by using the Causes and Effects Tool.
See Also
Using the Causes and Effects Tool
Displaying EffectsTo display the effects of a data cube:
Select a data cube whose effects you want to display.
To select several data cubes, hold down the Ctrl key and select the data cubes.
Select Tools, Analytic Model, Effects.
Select one of these options:
Direct Effects.
All Effects.
The Causes and Effects dialog box displays either the direct effects or all (direct and indirect) effects of the data cube. You expand any of the data cubes in the dialog box to view their attached dimensions.
Click OK when you have finished viewing the effects.
Note. You can also display effects by using the Causes and Effects tool.
See Also
Using the Causes and Effects Tool
Using the Causes and Effects ToolSelect Tools, Analytic Model, Causes and Effects Tool to browse through the cube collections and data cubes of your analytic model to view the causes, effects, and inputs of data cubes.
|
Cube Collection |
Select the cube collection to display a list of its data cubes. Note. You can also select <All Cubes> to display a list of all data cubes in the analytic model. |
|
Cubes |
Displays the names of the data cubes in the selected cube collection or the analytic model. Select a data cube to view its causes, inputs, or effects. To select several data cubes, hold down the Ctrl key and select the data cubes. |
Note. You can also audit individual data cubes by selecting the data cube, and then selecting Tools, Analytic Model and the desired audit option from the menu bar.
See Displaying Causes and Inputs, Displaying Effects.