
 Deduction Processing
Deduction Processing
This chapter discusses:
Deduction processing.
Export processing.
Import processing.
Interface definitions.
Table management.
Deduction Processing
This section discusses:
Deduction Calculation process flow.
DED_LINE and DED_CALC tables.
Deduction processing and multiple jobs.
Deduction Calculation Process FlowThis diagram illustrates the Deduction Calculation process flow:
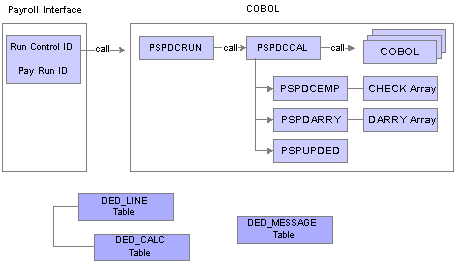
Payroll Interface Deduction Calculation process flow
Deduction processing occurs in the following way:
To start the Deduction Calculation process, enter a pay run ID and other parameters using the Calculate Deductions (RUNCTL_DED_CALC) component, Deduction Calculation page.
PSPDCRUN reads the pay run ID and calls PSPDCCAL.
PSPDCCAL calls the COBOL routines required to process deductions.
PSPDCCAL calls PSPDCEMP, which in turn creates the CHECK array.
PSPDCCAL calls PSPDARRY, which in turn creates the DARRY array.
PSPDCCAL calls PSPUPDED, which populates the DED_LINE and DED_CALC tables.
PSPDCCAL calls PSPDCEMP
The PSPDCEMP COBOL routine:
Selects the jobs and benefit programs to be processed by PSPDARRY.
Stores the EMPL_RCD and BEN_RCD that might exist for the EMPLID in the CHECK array.
PSPDCCAL calls PSPDARRY
The PSPDARRY COBOL routine:
Uses the CHECK array to select and calculate the deduction values that should be taken from an employee's check.
Stores the calculated deduction values in the DARRY array.
PSPDCCAL calls PSPUPDED
The PSPUPDED COBOL routine writes the results of the Deduction Calculation process to the DED_LINE and DED_CALC tables.
Note. The EMPLID/EMPL_RCD key field combinations for an employee are determined using the CHECK and DARRY arrays.
DED_LINE and DED_CALC TablesPayroll Interface stores the results of the Deduction Calculation and Deduction Confirmation processes in three tables: DED_CALC, DED_LINE, and DED_MESSAGE.
This diagram illustrates the parent-child relationship between the DED_LINE and DED_CALC tables:
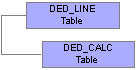
DED_LINE and DED_CALC tables
DED_LINE Table
The DED_LINE table stores the EMPLID and EMPL_RCD key fields that are required to identify and process an employee. The value of the PAY_LINE_STATUS field indicates whether the process finished successfully or failed. You can view the results using the Review Deductions (DED_CALCULATIONS) component, Calculated Deductions page.
Possible status indicators are:
|
Field |
Value |
|
PAY_LINE_STATUS |
|
DED_CALC Table
The DED_CALC table stores the EMPLID and EMPL_RCD key fields that are required to identify an employee as well as the results of the Deduction Calculation process, including the deduction codes and amounts for each. You can view results using the Review Deductions component, Calculated Deductions page.
DED_MESSAGE Table
The DED_MESSAGE table stores the EMPLID and EMPL_RCD key fields that are required to identify an employee and is populated only if an error occurs during the Deduction Calculation or Deduction Confirmation process. You can view the error messages using the Review Error Messages (DED_MESSAGE) component.
Deduction Processing and Multiple JobsTo calculate deductions for an employee with multiple jobs, the following criteria is used:
An employee with multiple jobs can have different benefit programs for each job.
If an employee has multiple jobs, some of which use the same benefit program, one of the jobs must be selected as the primary job.
If an employee has multiple jobs, all of which use different benefit programs, each job is selected as the primary job.
Deductions are calculated only for primary jobs.
This table shows possible job and benefit program combinations for three employees:
|
EMPLID |
EMPL_RCD |
Benefit Program |
Benefit Record Number |
Primary Benefit Job |
|
8412 |
0 |
BAS |
0 |
Y |
|
8412 |
1 |
FLX |
1 |
Y |
|
8412 |
2 |
FLX |
1 |
N |
|
8200 |
0 |
BAS |
0 |
Y |
|
8300 |
0 |
BAS |
0 |
Y |
|
8300 |
1 |
BAS |
0 |
N |
Benefit deductions use key fields EMPLID and EMPL_RCD. General deductions use key fields EMPLID and COMPANY (but not EMPL_RCD). Because the key fields are not the same, benefit deductions and general deductions are processed differently. The following tables show the deduction results for the employee whose EMPLID is 8421.
CHECK Array:
|
EMPLID |
Benefit Program (index for more than one) |
BEN_RCD |
|
8421 |
BAS |
0 |
|
8421 |
FLX |
1 |
DARRY Array:
|
Benefit Plan |
Benefit Program |
BEN_RCD |
|
20 Life |
BAS |
0 |
|
00 (general) |
none |
999 |
|
20 LifeX |
FLX |
1 |
DED_CALC table results:
|
Company |
Pay Group |
Pay End Date |
EMPLID |
EMPLID_RCD |
Plan Type |
Benefit Plan |
|
PST |
WK1 |
07/03/00 |
8412 |
0 |
20 |
LIFE |
|
PST |
WK1 |
07/03/00 |
8412 |
0 |
00 |
none |
|
PST |
FLX |
07/03/00 |
8412 |
1 |
20 |
LIFEX |
In the preceding example, Payroll Interface treats each EMPLID/EMPL_RCD key field combination as a separate row of information; each job is treated as a separate check. The EMPLID and all multiple jobs will be run through the deduction calculation process. Although a separate row is created for each multiple job in the payroll interface, all of the employee’s multiple job deductions are processed at the same time.
In the preceding example, general deductions should be taken against only one of the jobs. However, because general deductions do not include the EMPL_RCD key field, you must manually select the EMPL_RCD using the Payroll Options (PAYROLL_DATA) component, Payroll Options 2 page, Deduction Calc Record field. The Deduction Calc Record (Deduction Calculation Record) field appears for employees who have:
Multiple jobs in the same company.
Different benefit programs for each job.
General deductions.
See Also
Export Processing and Multiple Jobs
Export ProcessingThis section discusses:
Export process flow.
Export process details.
PI_PARTIC and PI_PARTIC_EXPT tables.
PI_EXTIO and PI_PARTIC_EXTBL tables.
Export processing and multiple jobs.
Export Process FlowThis diagram illustrates the Export process flow:
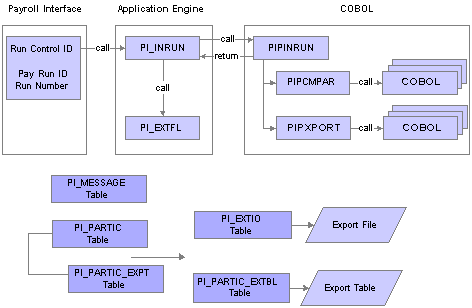
Payroll Interface Export process flow
Export processing occurs in the following way:
To start the Export process, use the Import/Export Payroll Data (PI_RUNCTL_PNL) component, Import/Export Payroll Data run control page to enter the pay run ID, payroll interface run number, and other parameters.
PI_INRUN reads the pay run ID and run number and calls PIPINRUN.
PIPINRUN calls PIPCMPAR (which in turn calls other subroutines). PIPCMPAR selects, compares, and exports data to tables PI_PARTIC and PI_PARTIC EXPT.
PIPINRUN calls PIXPORT (which in turn calls other subroutines). PIPXPORT reads table PI_PARTIC_EXPT, transfers the changed data to temporary table PI_EXTIO or PI_PARTIC_EXTBL.
PIPINRUN returns control to PI_INRUN.
PI_INRUN calls PI_EXTFL.
If exporting to a file, PI_EXTFL reads the data in PI_EXTIO and creates the export file. If exporting to a table, PI_EXTFL reads the data in PI_PARTIC_EXTBL and creates the export table.
Export Process Details
The Export process includes three phases — select, compare, and export:
During the select phase, payroll data is retrieved from the PeopleSoft Enterprise HRMS tables.
During the compare phase, the selected data is compared against the data from the previous export run.
The comparison phase identifies any data changes that have occurred since the last export.
During the export phase, the data is exported to either a flat file or a table.
A full-records export performs the select and export phases; all data is exported. A changes-only export performs the select, compare, and export phases; only data that has changed is exported.
PI_INRUN calls PIPINRUN
Export processing is based on the pay run ID and run number. For each pay run ID, PIPINRUN retrieves the company and pay group from the pay calendars. The company and pay group are used to verify the payroll interface definitions and to select the employees who will be processed.
PIPINRUN calls PIPCMPAR
First, PIPCMPAR verifies the payroll interface setup for the selected configuration ID:
Using the company and pay group, PIPCMPAR obtains the configuration ID from the Pay Group table.
Using the configuration ID, it retrieves the file definitions and the system ID from the Configuration table.
For the selected system ID, PIPCMPAR verifies all records and fields in PS Tables table.
For the selected system ID, PIPCMPAR verifies all fields in the Field Definition table.
PICMPAR verifies that all the parameters defined in the Definition table are valid.
Using the company and pay group, PIPCMPAR selects from the Job table all employees (with status values defined in the System table) with a matching company and pay group.
Second, PIPCMPAR performs the actual export process. The export process differs for full-records exports and changes-only exports.
For a full-records export, PIPCMPAR does the following for each selected employee in the pay group:
For each table defined in PS Tables, retrieves rows based on the where clause definition (as well as instance IDs, process IDs, and other information that is set up in the interface).
Exports the results to tables PI_PARTIC and PI_PARTIC_EXPT in the format specified in the Definition table (LOG, PHY, CSV, and so on).
Note. For full-records exports, all values are considered new, and therefore, changed. Flags in the PI_PARTIC and PI_PARTIC_EXPT tables are initialized to Y and 1.
Changes-only export, PIPCMPAR, does the following for each selected employee in the pay group:
For each table defined in PS Tables, retrieves rows based on the where clause definition (as well as instance IDs, process IDs, and other information that is set up in the interface).
Compares the value of each field (and row, if designated) to the value that was sent in the last export (the previous run number).
Exports the results to table PI_PARTIC and PI_PARTIC_EXPT in the format specified in the Definition table (LOG, PHY, CSV).
Note. For changes-only exports, flags in the PI_PARTIC and PI_PARTIC_EXPT tables are set to Y and 1 if values change or to N and 0 if values do not change.
PIPINRUN calls PIPXPORT
PIPXPORT reads table PI_PARTIC_EXPT and writes the changed data to temporary table PI_EXTIO or PI_PARTIC_EXTBL.
Note. If no changes occurred, table PI_EXTIO or PI_PARTIC_EXTBL is empty at the end of the export process.
PI_INRUN calls PI_EXTFL
When the export processing is finished, control returns to the Application Engine. PI_INRUN calls PI_EXTFL to create the export file.
PI_EXTFL does the following:
For each row of data in table PI_EXTIO:
ook.Writes a line to the export file defined in the File Handle table for the file definition. The data is written in the character set defined on the PI System table (LOG, PHY, CSV, and so on).
Deletes the contents of table PI_EXTIO.
Deletes the run control record.
PI_PARTIC and PI_PARTIC_EXPT TablesWhen a full-records or changes-only export is processed, flags are set in the PI_PARTIC and PI_PARTIC_EXPT tables. The values of these flags determine which data is written to the export file (or table).
This diagram illustrates the parent-child relationship between the PI_PARTIC and PI_PARTIC_EXPT tables:
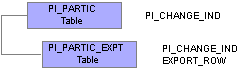
PI_PARTIC and PI_PARTIC_EXPT tables
The PI_PARTIC table contains one row of data for every employee and for every process. It contains high-level information that determines which employees are processed during the comparison phase. Two key fields in this table are EMPLID and PI_RUN_NUM. The PI_RUN_NUM is very important when doing a reprocess run. A critical field on the PI_PARTIC table is PI_CHANGE_IND. If an employee has had a data change since the last Export process, the PI_CHANGE_IND flag is set to Y.
The PI_PARTIC_EXPT table contains the historical (changed) data for the comparison phase. New rows are inserted into this table during each Export process run. Every field that will be sent to the third-party payroll system is in this table. In front of each data element on the PI_PARTIC_EXPT table is a change flag. If the field has changed since the last process, this flag is set to 1; otherwise, it is set to 0. If the field belongs to a group, the data element is prefixed with 2.
Within the PI_PARTIC_EXPT table, the Export Row column is a 250-byte character representation of employee-level data. This data field is the result of information that is set up using the Definition Table (INTRFC_DEFINITION) component. If there is more than 250 bytes of data, another row is inserted into the table and the EXPORT_SEQ is incremented. The export row is positional and is based on the order of the fields that are set up using the Definition Table component. This is very important for maintenance during live processing.
If values change, PI_CHANGE_IND is set to Y.
Possible run status indicators for a successful export run are:
|
Field |
Value |
|
PI_PARTIC_STATUS |
Note. When the process finishes, the flag should be set to C or E. If the flag is set to P, then an error has occurred. |
|
PI_CHANGE_IND |
Note. Some data changes trigger a process; for example, if an employee is terminated, a stop transaction for deductions may be issued. |
|
PI_CHANGE_TYPE |
|
If values change, PI_CHANGE_IND is set to Y and the byte-length field flags that are attached to each field value are set to 0, 1, or 2. All exported data is written to EXPORT_ROW, a 250-character field. If the export file is defined at a length greater than 252 characters, then data is loaded into additional EXPORT_ROW fields and the EXPORT_SEQ sequence field is incremented.
Possible run status indicators for a successful export run are:
|
Field |
Value |
|
PI_CHANGE_IND |
|
|
EXPORT_ROW |
|
Example 1
Suppose the following for the employee with EMPLID KUI001:
Full-records export, run number 1.
Data values for salary, union dues, savings bond, and vehicle allowance.
|
Export |
Run Num |
Salary |
U-Dues |
SV-BND |
VEH |
|
Full-records |
1 |
1500 |
10 |
100 |
15 |
PI_PARTIC table—This is a full-records export and all data values are considered changed. PI_CHANGE_IND is set to Y.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
1 |
|
PI_CHANGE_IND |
Y |
PI_PARTIC_EXPT table—PI_CHANGE_IND is set to Y and the byte-length field flag is set to 1 for all data values.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
1 |
|
PI_CHANGE_IND |
Y |
|
EXPORT_ROW |
11500 110 1100 115 |
Export file—All data values are written to the export file (or table).
|
Employee (EMPLID) |
Salary |
U-DUES |
SV-BND |
VEH |
|
KUI001 |
1500 |
10 |
100 |
15 |
Example 2
Suppose the following for the employee with EMPLID KUI001:
Changes-only export, run number 2.
Data values for salary and savings bond have changed.
|
Export |
Run Num |
Salary |
U-Dues |
SV-BND |
VEH |
|
Full-records |
1 |
1500 |
10 |
100 |
15 |
|
Changes-only |
2 |
1800 |
10 |
150 |
15 |
PI_PARTIC table—PI_CHANGE_IND is set to Y.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
2 |
|
PI_CHANGE_IND |
Y |
PI_PARTIC_EXPT table—PI_CHANGE_IND is set to Y and the byte-length field flag is set to 1 for data values that have changed and to 0 for data values that have not changed.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
2 |
|
PI_CHANGE_IND |
Y |
|
EXPORT_ROW |
11800 010 1150 015 |
Export file—Changed data values are written to the export file (or table).
|
Employee (EMPLID) |
Salary |
U-DUES |
SV-BND |
VEH |
|
KUI001 |
1800 |
150 |
Example 3
Suppose the following for the employee with EMPLID KUI001:
Changes-only export, run number 3.
No data values have changed.
|
Export |
Run Num |
Salary |
U-Dues |
SV-BND |
VEH |
|
Full-records |
1 |
1500 |
10 |
100 |
15 |
|
Changes-only |
2 |
1800 |
10 |
150 |
15 |
|
Changes-only |
3 |
1800 |
10 |
150 |
15 |
PI_PARTIC table — PI_CHANGE_IND is set to N.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
3 |
|
PI_CHANGE_IND |
N |
PI_PARTIC_EXPT table — PI_CHANGE_IND is set to N and the byte-length field flag is set to 0 for all field values.
|
Field |
Values |
|
EMPL_ID |
KUI001 |
|
PI_RUN_NUM |
3 |
|
PI_CHANGE_IND |
N |
|
EXPORT_ROW |
01800 010 0150 015 |
Export file — No data values have changed; no data is written to the export file (or table).
|
Employee (EMPLID) |
Salary |
U-DUES |
SV-BND |
VEH |
|
KUI001 |
PI_EXTIO and PI_PARTIC_EXTBL TablesThe Export process can write data to either an export file or an export table.
This diagram illustrates exporting data to either a file or table:
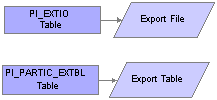
PI_EXTIO and PI_PARTIC_EXTBL tables
PI_EXTIO Table
In the PI_EXTIO table, the REC_DATA_PARTIAL field should contain the exact contents of the external file. However, if the record length of the external file exceeds 252 bytes, then the rows in PI_EXTIO are split and the RECDATA_SEQ_NO field is incremented.
PI_PARTIC_EXTBL Table
In the PI_PARTIC_EXTBL table, a row for each changed field is written and the SEQ_NUM field is incremented by 1 unless the field has a group ID assigned to it. For fields with group IDs, the same SEQ_NUM is applied to all fields in the group. For the sequence numbering logic to work properly, you must set up grouped fields correctly. For example, the DED group ID can be used to pair the Deduction Code and Deduction Amount fields. These two fields must adjoin each other on the record; fields without the DED group ID cannot be positioned between them.
See Setting Up the Definition Table.
Export Processing and Multiple JobsTo export data for an employee with multiple jobs, the following criteria is used:
An export record is created for each job that is set up with a Payroll Interface company/pay group.
All records that use the employee record number in the key send the appropriate data for that record number.
All records that do not contain the employee record number in the key (for example, personal data) send the same information that applies to all export records.
All of the employee's jobs are exported, whether the jobs are from the same or different pay groups or the same or different companies.
When a concurrent job is added or terminated, it is processed the same way that a single job is added or terminated.
If you define unique IDs by combining the PeopleSoft EMPLID and record (job) number, you create separate employees in the third-party payroll system for each job.
If you use multiple jobs in PeopleSoft Enterprise HRMS, but only want to export a single job through Payroll Interface, you might instead identify a particular job record number for all employees, then create an instance ID attached to the record-mapped-to job, to include only that specific job record number.
Payroll System IDs
You can add another key besides the PeopleSoft EMPLID, the national ID, and the payroll interface employee ID. You can use a view, the multiple national ID field on the personal data pages, or the Payroll Interface existing translation logic. The approach that you choose depends on the third-party payroll requirements.
If you need a single check, create a view to combine the values into one amount for each deduction code. Payroll Interface treats each employee ID or employee record number as a separate row of information. Each job is treated as a separate check. This gives you tremendous flexibility when mapping information to the third-party payroll system.
See Also
Deduction Processing and Multiple Jobs
Import ProcessingThis section discusses:
Import process flow.
Import tables.
Import Process Flow
This diagram illustrates the Import process flow:
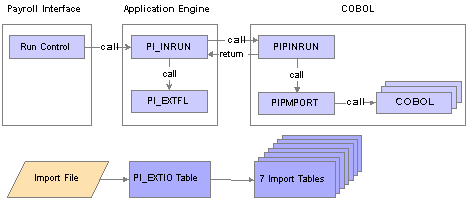
Payroll Interface Import Process flow
Import processing occurs in the following way:
To start the Import process, enter a pay run ID, run number, and other parameters using the Import/Export Payroll Data component, Import/Export Payroll Data run control page.
PI_INRUN reads the run control record and calls PI_EXTFL.
PI_EXTFL loads the import file into table PI_EXTIO and returns control to PI_INRUN.
PI_INRUN calls PIPINRUN.
PIPINRUN calls PIPMPORT (which in turn calls other subroutines).
PIPMPORT reads the PI_EXTIO table and loads the data into seven import tables.
PIPINRUN returns control to PI_INRUN.
PI_INRUN deletes the PI_EXTIO table and the run control.
Import TablesPayroll Interface uses seven import tables to store the payroll results that are generated by the third-party payroll system. The import tables include many user-defined fields. You do not need to map data to all of these fields, but you do need to map to a few, such as check number and gross wages. The import tables are:
PI_CHECK
PI_EARN_DETAIL
PI_DED_DETAIL
PI_TAX_DETAIL
PI_EARN_BAL
PI_DED_BAL
PI_TAX_BAL
Note. After the Import process is run, further processing or technical configuration may be required to check the validity of the data or to ensure that employee-level data can be accessed in a secure manner.
To import numeric and signed numeric fields, the data value in the import file must not contain any spaces. For example, to import a numeric field with a length of 10, decimal length of 2, display decimal enabled, and a value of 10.22, the value in the data file must equal 0000010.22 (leading zeros), and not bbbbb10.22 (where b represents a blank space).
Payroll Interface does not perform reverse translations (mappings). The data loaded into the import tables resides in the third-party payroll system's format. For example, suppose you select the Using Interface Employee Table option for the System Table (SYSTEM_TABLE) component, Interface System Table 1 page, Convert field. During the Export process, the PeopleSoft EMPLID is translated to the third-party payroll system employee ID, and the third-party payroll system employee ID is written to the export file or table. During the Import process, however, no reverse translation takes place. The third-party payroll system employee ID is loaded into the Payroll Interface import tables.
Note. If you select the Using Interface Employee Table option, the data in the Payroll Interface import tables can be joined to other PeopleSoft EMPLID-keyed tables through the PI_EMPLID_TBL table. This table includes the EMPLID, EMPL_RCD, and PI_EMPLID fields.
See Also
Interface DefinitionsThis section discusses:
Testing exports and imports.
Successful exports.
Unsuccessful exports.
Detecting errors.
Testing Exports and Imports
To test export and import interface definitions, run the Payroll Interface Export and Import processes until no errors occur and the data results are correct. Import interface definitions are usually set up and tested after the export interface definition is verified.
Testing Exports
To test an export interface definition the first time:
Delete the contents of the Payroll Interface tables shown below.
(optional) Run the Deduction Calculation and Confirmation processes.
Run a full-records Export process.
Use the Pay Run ID prior to the pay run that is to be used for production.
When the Export process completes, check for errors.
Delete the content of these tables before running the Export process the first time:
|
Process Tables (Export) |
||
|
|
|
Testing Imports
To test the import interface definition the first time:
Delete the contents of the Payroll Interface tables shown in the succeeding table.
Obtain a copy of the import file that is produced by the third-party payroll system.
Run the Import process.
Use the pay run ID for the associated Export process.
When the Import process finishes, check for errors.
Delete the content of these tables before running the Import process the first time:
|
Process Tables (Import) |
||
|
|
|
See Also
Successful Exports
You can identify a successful export run in the following ways:
Changes that occurred during the pay period to PeopleSoft Enterprise HRMS mapped-data elements are exported and written to a file or table.
The compare process identifies correct changes.
The implementation of additional processing logic (beyond the delivered supported application functionality) works correctly, including:
Modifying the delivered Payroll Interface COBOL, for example, creating a new process ID.
Processing files using Application Engine, Structured Query Report (SQR), or other programming languages, for example, reformatting a record layout.
Writing PeopleCode, for example, to force a new set of export records given a specific job action (that is, rehire or transfer).
Creating new views, incorporating any American National Standards Institute (ANSI) SQL statement. For example, join the Department table with Job to extract department GL expense codes or managers, develop specific WHERE clauses, and perform Logic/Arithmetic/SQL functions.
The contents of the export file (or table) are imported into the third-party payroll system and the data elements and transactions have been processed accurately per the third-party payroll system’s import processing requirements. These types of transactions involve updating, inserting, or deleting employee data.
Unsuccessful Exports
For debugging purposes, sometimes it may be useful to run the PIPINRUN process directly. First, use the Import/Export Payroll Data component, Import/Export Payroll Data run control page to enter and save the Run Control ID and Pay Run ID. Then, instead of submitting the request to the process scheduler using the RUN button, run PIPINRUN at the command line of the process server or any connected computer with fully compiled current COBOL. During the run, PIPINRUN calls PIPCMPAR and PIPXPORT, the results are written to the PI_EXTIO table, and then processing stops. To rerun the PIPINRUN process, the contents of the PI_EXTIO table as well as the PI_RUNCTL table must be deleted.
Example 1
Export Result: PI_PARTIC and PI_PARTIC_EXPT are both empty.
If the failure of the export is not obvious, for example, the process terminates or a Payroll Interface error message such as MISSING RUN CONTROL is displayed, then analyze the employees. The Pay Run ID determines the pay calendar's company and pay group. PIPCMPAR selects against JOB.COMPANY and JOB.PAYGROUP to retrieve the appropriate employees. The DMS statement used in PIPCMPAR.DMS to select these employees performs an insert into PI_PARTIC. Therefore, if PI_PARTIC is empty, it is because the PIPCMPAR SQL that is trying to select employees and do the insert failed.
Most likely, an interface error message is in PI_MESSAGE stating that there were no records to export. However, to determine why no employees were selected, you will need to analyze the pay run ID, the associated pay calendar, the Pay Group table, and the corresponding employee job records.
Example 2
Export Result: PI_PARTIC is loaded and PI_PARTIC_EXPT is empty.
If the PI_PARTIC table is loaded, then the Export process select phase was successful (which means that the pay run ID, the pay calendar, the Pay Group table, and the Job records were set up correctly). If the process did not end, but the PI_PARTIC_EXPT table is empty, then the Export process compare phase was not successful. Do an inquiry on the interface messages (PI_MESSAGE) to determine why the process failed. When all of the issues are fixed, you should be able to reprocess the export.
Example 3
Export Result: PI_PARTIC is loaded, PI_PARTIC_EXPT is loaded, PI_EXTIO is loaded (when it should be empty) and no export file is created.
If PI_EXTIO is loaded, the Export process select, compare, and export phases finished successfully. However, the Application Engine’s file I/O process that writes the contents of PI_EXTIO to the export file (and then deletes PI_EXTIO) did not finish successfully. Make sure the file IDs and file handles are set up correctly. If they are, then analyze the Application Engine programs PI_INRUN and PI_EXTFL.
Note. This does not apply if you are exporting data to a table.
Example 4
Export Result: PI_PARTIC is loaded, PI_PARTIC_EXPT is loaded, PI_EXTIO is empty, and no export file is created.
This scenario could mean that the Export process was successful and no changes exist. It also could mean that the Export process was successful and the external file was created, but the file is not located where you expected it.
If known data changes have occurred and the file cannot be found, then evaluate the PSPSEQIO COBOL program for issues surrounding the insert into the PI_EXTIO table. It would be helpful to run the COBOL process separately to insure that PI_EXTIO is being loaded at the end of the compare and export phases. At that point, the analysis should shift to the Application Engine’s write to the external file.
Note. This does not apply if you are exporting data to a table.
See Also
Detecting Errors
To determine whether an error has occurred after running the Deduction Calculation or Deduction Confirmation processes, first refer to the Review Deductions and Review Error Messages components.
See Reviewing Deductions.
To determine whether an error has occurred after running the Export or Import processes, first refer to the Error Messages (PI_MESSAGES) component and various reporting components.
See Reviewing Exports or Imports.
If the explanation in the Error Message component is not clear, you can use the message number to determine where in the COBOL routine the problem occurred. For example, suppose message 004030 returns the following information:
The Dedcalc process was not confirmed. This data is not available until the confirm is processed. The message data below identifies 2 field values. 1. Company 2. Paygroup.
To locate the problem:
Search for 004030 in PSCPYMSG.CBL to determine the corresponding 88 level name for MSGID.
In this case, it is MSGID-DEDCALC-NOT-CONFIRMED.
Using a search tool, do a search against PI*.CBL to look for all the occurrences of MSGID-DEDCALC-NOT-CONFIRMED.
The result is in PIPINRUN.CBL, paragraph MM100-CONFIRM-DEDCALC.
The location of the error in the COBOL routine may point to a SQL statement or array search that may give additional clues to the problem.
Error: Dynamic SQL Failure Due to Invalid PS Table Setup
If you use PeopleSoft Application Designer to change any of the tables or fields that are set up in the PS Tables (PS_TABLES) component, you must make sure that these changes are reflected in the PS Tables component as well. If you do not, the Export process will end when attempting to run the dynamically created SQL statement. If it is not obvious which table or field is causing the error, you can run the Export process from a DOS prompt.
To run PIPINRUN from the DOS prompt:
From the DOS prompt, run PIPINRUN with the SQL Trace turned on.
At the SQL Trace prompt, enter 191.
A trace file is written to C:\TEMP\PS\<dbname>\COBSQL_. The SQL causing the process to end should be toward the end of the trace file with a SQL statement name such as S_JOB, S_GENL_DEDUCTION, and so on.
Copy the SQL to the database’s SQL Inquiry tool and run it using the parameters listed below the statement in the trace file.
The SQL Inquiry tool should point to the problem field.
See Enterprise PeopleTools 8.45 PeopleBook: PeopleSoft Application Designer
Error: Maximum Number of Export Records Exceeded for EMPLID
PIEXPT-COUNT-MAX represents the maximum number of records that can be generated for an EMPLID. During the Export process, this maximum number can be reached when you are processing files that comprise a high number of rows in PS_JOB.
PIEXPT-COUNT-MAX is set to 200 by default. If you want to increase this number, you need to modify to the COBOL in two places:
In PICIEXPT.CBL, insert the desired number where you see 200 in bold.
88 PIEXPT-COUNT-MAX VALUE 200
In PIPIEXPT.CBL, insert the desired number where you see 200 in bold.
02 PIEXPT-DATA OCCURS 200
Be sure to recompile the programs when you are done.
You may encounter similar error messages for “Maximum number of export records exceeded.” Again, just follow the code line through and increase the 88 VALUE and the corresponding OCCURS values.
Table ManagementPayroll Interface is a table-driven export and import engine. As you set up and maintain an interface definition, you may need to work directly with various Payroll Interface tables.
Note. If using PeopleSoft Data Mover to run DELETE, IMPORT, and EXPORT scripts, use the internal name for the table, for example, PI_PARTIC. If using Microsoft SQL Query Analyzer or some other non-PeopleSoft tool to run SQL statements, use the external name for the table, for example PS_PI_PARTIC.
See Enterprise PeopleTools 8.45 PeopleBook: Data Management
Managing the Process Tables
Occasionally, you may want to delete the data in the Payroll Interface process tables to free disk space, reduce processing times, or send a full record export file to the third-party payroll system.
Warning! PeopleSoft does not support a specific purge strategy. Back up tables before you run the SQL DELETE statement.
To purge the process tables, follow these general guidelines:
Stop all data input into the PeopleSoft system.
Run the normal daily process (usually a changes-only export run).
Delete the data in the selected process tables.
Run the normal daily process again (the system will return by default to a full-records export run).
You should delete the data in the tables whenever changes are made to the export file definition (for example, changing field characteristics such as increasing or decreasing field sizes or edit masks or adding or deleting fields from the interface definition).
The PI_PARTIC and PI_PARTIC_EXPT tables can get very large. You should monitor the size of these tables on a regular basis to ensure that Payroll Interface functions properly. You may want to archive historical data in these tables.
The PI_RUN_TBL tables contains the PI_RUN_NUM field. If you purge this table, the PI run number is reset to 1. If you do not want to reset run number, do not purge the PI_RUN_TBL or the PI_RUN_PYGRP tables. When you run the Export process, the run number will be incremented to the next number.
Warning! Do not purge the PI_EMPLID_TBL if you have mapped the PeopleSoft EMPLID to the third-party payroll system employee ID.
The Payroll Interface process tables include:
|
Process Tables |
||
|
|
|
Managing the Control Tables
Occasionally, you may want to transfer the Payroll Interface control tables (also referred to as the setup tables) from one database to another for example, when you move from a test environment to a production environment.
Warning! Never copy the process tables (PI_PARTIC, PI_PARTIC_EXPT, and so on) from a test environment to a production environment. These tables are automatically populated in the production environment.
To export tables, run this script:
|
SET LOG C:\TEMP\PI_EXPORT.LOG; SET OUTPUT C:\TEMP\PI_TABLES.DAT; EXPORT PI_SYSTEM_TBL; EXPORT PI_SYSTEM_STAT; EXPORT PI_SYSTEM_LANG; EXPORT PI_PS_RECORD; EXPORT PI_PSREC_FLD; EXPORT PI_PS_REC_LANG; EXPORT PI_INSTANCE_TBL; EXPORT PI_INST_VALUE; EXPORT PI_INSTANC_LANG; EXPORT PI_PROCESS_TBL; EXPORT PI_PROCESS_VAL; EXPORT PI_PROC_TB_LANG; EXPORT PI_PROC_VA_LANG; EXPORT PI_FIELD_TBL; EXPORT PI_FIELD_XLAT; EXPORT PI_FIELD_LANG; EXPORT PI_GROUP_TBL; EXPORT PI_GROUP_LANG; EXPORT PI_DEFN_FILE; EXPORT PI_DEFN_RECORD; EXPORT PI_DEFN_FIELD; EXPORT PI_DEFN_F_LANG; EXPORT PI_DEFN_R_LANG; EXPORT PI_CONFIG_TBL; EXPORT PI_CONFIG_FILE; EXPORT PI_CONFIG_LANG; EXPORT FILE_HANDLE_LNG; EXPORT FILE_HANDLE_TBL; |
To import tables, run this script:
|
SET LOG C:\TEMP\PI_IMPORT.LOG; SET INPUT C:\TEMP\PI_TABLES.DAT; REPLACE_ALL *; |
|
SET LOG C:\TEMP\PI_IMPORT.LOG; SET INPUT C:\TEMP\PI_TABLES.DAT; IMPORT * IGNORE_DUPS; |
REPLACE_ALL *;—Deletes all data from the PeopleSoft table and replaces it with the data in your import file.
IMPORT * IGNORE_DUPS;—Leaves all data in the PeopleSoft table and loads only new rows of data. It will not replace any data already in the table. So if you have a row that exists in both the source table and the target table, no action is taken at all, even if some of the fields on that row have changed