
 Understanding the Core Application Architecture
Understanding the Core Application ArchitectureThis chapter provides overviews of the core application architecture, elements, the processing framework, the batch architecture process, and discusses how to define the installation settings.
Understanding the Core Application ArchitectureAbsence Management is built on a core application that organizations in all countries can use to create absence and payroll management systems. Understanding the core application architecture will enable you to better understand the complex details of Absence Management.
Understanding Elements
When you create your absence management system using Absence Management, you want to be sure that it meets all the requirements of your organization. One of the ways that PeopleSoft ensures this is by building the absence management system through the use of components called elements.
This section discusses:
What is an element?
Combining elements into rules.
Why the core product uses element name number (PIN) processing.
What Is an Element?An element is the smallest component of Absence Management. Elements are building blocks that relate to other building blocks to define your absence management system.
You define each element only once and use it repeatedly anywhere in the system.
This table lists the element categories:
|
Type of Element |
Description |
|
Data retrieval |
Retrieves data. Some are predefined elements (called system elements) that are delivered by PeopleSoft. Others you define when creating your absence management system. |
|
Calculation |
Performs a calculation. |
|
Organizational |
Defines the structure and framework for the system. |
This table lists alternative element categories:
|
Type of Element |
Description |
|
Primary |
Represents primary rules for absence takes and entitlements. |
|
Supporting |
Usually not used alone, but used to create other, more complex elements. |
|
Miscellaneous |
Represents such things as eligibility criteria, accumulators, and certain types of rules. |
You can combine these elements in an unlimited number of ways to produce the results that you need for your absence management processing.
See Also
Defining General Element Information
Combining Elements Into RulesIn Absence Management, you create and store rules by entering data through the online pages.
These rules drive the core application and define the absence management process. Think of a rule as what defines how an element is calculated. Rules define the absence management process itself.
Each country using Absence Management defines its own rules. Absence Management enables you to define rules that address your specific absence management processing needs.
This diagram shows how elements and rules define your absence management process:
![]()
Elements are manipulated by rules to create the absence management process
Important! There is usually no need to modify the Absence Management COBOL programs. Using the online pages, you can configure the system to meet your absence management processing needs. PeopleSoft strongly discourages the modification of the delivered COBOL programs—with the possible exception of modifying array size—because modifications can affect the integrity of the entire system.
See Also
Why the Core Application Uses Element Name Number (PIN) ProcessingAn element name number is a numeric identifier for an element. Every element in Absence Management has a unique element name number, including the elements that you create and the elements the PeopleSoft system delivers. Absence Management programs access and process an element by referring to its element name number, rather than its name.
A PIN is referred to as an element in Absence Management. A PIN and an element are identical, and a element name number is the same as an element number. We explain the term PIN here because it is referenced throughout the programs and table structure of the application. Think of PIN as the technical name that is used in the programming and table structure and element as the functional name that is used on all pages and discussions.
This is necessary because Absence Management is designed for use by any organization in any country. Each organization will likely give the elements that form the basis for its absence management system different names, depending on its requirements. And organizations in different countries are going to name their elements using different languages. Also, the system elements delivered by PeopleSoft are often translated into many languages. If the name were the only way to identify an element, there could be problems.
One problem would be background processing errors. If elements were referenced only by name, and you tried to run an absence process after having renamed an element, then the programs would not know how to access that element. By having the element represented by a unique and constant number (the element name number), the programs always know that they're referencing the correct element during processing.
Element name numbers also improve performance within batch processes. It is more efficient for the system to use numeric values than to use character values. This performance improvement is a result of being able to easily read the numeric values into the processing arrays and create a pointer to the correct place in the array.
PINs are numbered sequentially.
Note. The system assigns a element name number to each element that you create. The first number the system assigns is 100,001. Element name numbers prior to 100,001 are reserved for the elements that are delivered with Absence Management.
Elements are accessed by element name number, rather than by element name, as shown in the following graphic:
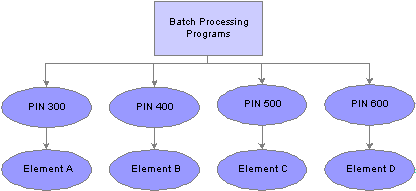
Elements are accessed by pin number rather than element name
Understanding the Processing FrameworkThe Absence Management core application is a common foundation and structure that organizations use to build their own calculation rules. The core application determines the basic framework for your absence processing. This framework supplies the normal processing sequence, organizational structure, and processing structure for calculating absences.
This section discusses:
The processing sequence.
The organizational structure.
The processing structure.
Calendars.
The Processing SequenceAn absence process consists of several processing phases, some of which you can run together. The typical processing sequence (the order in which Absence Management executes phases of a batch process for an absence run consists of these phases:
Identification (payee selection)
Calculation
Finalization
You can also run Cancel, Freeze, Unfreeze, and Suspend phases as needed and modify processing instructions by payee.
When you first launch the batch process, Absence Management determines which payees are to be selected and calculated for the absence run, based on the selection criteria that you have specified. This identification phase is executed only once for each calendar group ID.
During the calculation phase, absence calculations are performed. Each payee is processed sequentially. As the system encounters each payee, it processes each element that is identified in the process list. Various criteria such as eligibility and generation control are considered in selecting which elements to process.
The calculation process can be repeated any number of times; only the absences that are appropriate to calculate are processed. When a calculation is first executed, all absences are processed. During subsequent calculations, only the following absences are processed:
Absences resulting from iterative triggers or positive input.
Absences for which you have entered recalculate instructions.
Absences that encountered errors during the previous run.
An iterative trigger can be produced when data changes for a payee. For example, a change to a payee’s job record might create an iterative trigger. Or the addition of a new hire to the calendar group ID can produce iterative triggers. An iterative trigger populates a process indicator field to indicate the type of iterative trigger.
Finalizing an absence run closes and completes the process.
See Also
The Organizational StructureThe Absence Management core application determines the organizational structure for absence management processing. This diagram shows the hierarchy of components in the organizational structure:
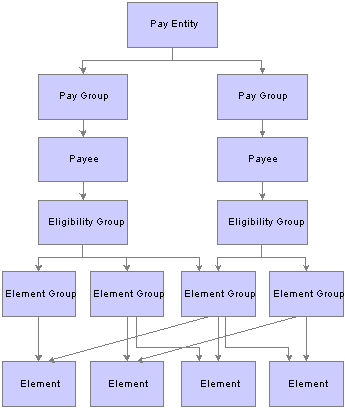
Organizational structure of Absence Management
Pay entity defines the organization that is managing absences for payees.
A pay entity can be linked to one or more paygroups. However, each paygroup is linked with only one pay entity.
You associate a specific country with each pay entity. This country designation is important for many features in Absence Management such as the groups of calendars with a single calendar group ID, retroactive methods, and trigger definitions.
Absence Management uses a logical grouping, called paygroup, to qualify individuals for absence management. Typically, all individuals in a paygroup have something in common that causes them to be processed at the same time in the absence management system.
Common examples of paygroups are salaried and hourly payees. You can assign a payee’s default absence elements based on paygroup if you select this option at installation time. A paygroup can be associated only with a single pay entity.
Each paygroup has a default eligibility group associated with it. This includes the default absence elements for the paygroup population. The default eligibility group that is associated with a paygroup is used as the payee level default. You can override these defaults.
Paygroups are ultimately associated with pay calendars to process absences. It is important to group payees whose absences are calculated with the same frequency—weekly, monthly, and so on.
Payees are the people in your organization for which you want to calculate absence results.
Payees who are included in a paygroup definition can be members of different eligibility groups. The only link between paygroups and eligibility groups is from a default perspective. The eligibility group that is defined on the Paygroup page is used as an initial default for the payee. You can override the default.
An eligibility group is a grouping of element groups. Eligibility groups indicate the specific elements for which a certain payee population is eligible. The default eligibility group is defined at the paygroup level. A payee is assigned to an eligibility group through the default that is defined at the paygroup level. You can override the default value.
For example, let's say that you have a paygroup for all payees whose absences are calculated monthly. Of those payees, 99 percent are regular, salaried payees. who are eligible for regular absence entitlements and takes. However, you also have 10 executives whom you want to include in that same paygroup. These executives are eligible for slightly different absence rules. You can override their eligibility group and assign them to the EXEC ABSENCES eligibility group. You can have only one default eligibility group for each paygroup.
Element groups provide a method of assigning a large number of elements to many eligibility groups without repeating the elements in each and every eligibility group. Element groups provide a means for grouping these elements. You can assign any number of element groups to an eligibility group.
Elements
Elements are the basic building blocks of Absence Management. The organizational structure of the system begins with the definition of these basic payroll components.
See Also
Defining the Organizational Structure
The Processing StructureThis diagram shows the components of the processing structure:
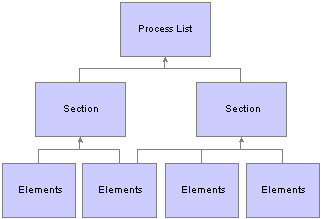
Processing structure of Absence Management
Process List
A process list specifies the order in which absence elements are processed and resolved. You add these elements to the process list by using sections. If you add sections to your process list, the sections are processed in the order in which you insert them into the list. You can also execute sections conditionally.
The Process List Definition page indicates that the type of calculation is absence.
Section
A section is a grouping of elements and controls the order that those elements are processed on the process list. You can use the following types of sections for absence processing:
Standard sections for regular processing.
Payee sections for specifying, at the payee level, elements for processing.
Absence take sections for processing absences in date sequence.
Once you have defined a section, you can reuse it in multiple process lists.
Elements
Elements are the basic building blocks in Absence Management. Some stand alone while others use several simple elements (called supporting elements) that are combined to form more complex elements.
During an absence processing run, the system resolves each element in the process list for each payee. The elements that are resolved depend on a payee, so the resolved value of an element depends on which payee is under consideration.
See Also
Understanding Processing Elements
Defining General Element Information
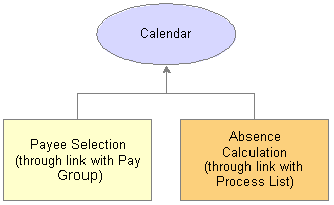
CalendarsTo run an absence process, the relevant components of the system are tied together through the use of calendars. A calendar controls whose absence results will be calculated, and the period of time for which the absences are processed.
Only one paygroup can be associated with a calendar. Through the use of various selection criteria, you can define who is going to be paid:
Calendar run types define the type of absence run; for example, a regular absence run or an off-cycle absence run.
Calendar period IDs define the period of time for which the absences are processed.
Calendar group ID groups the calendars that you want to process at the same time.
This diagram shows how calendars ties together the components of an absence run:
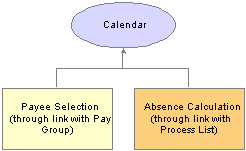
Calendar ties the entire process together
See Also
Understanding the Batch Architecture Process FlowThis section discusses:
Absence Management modes.
Payee selection.
Calculation (technical).
Arrays used in background processing (technical).
Background processing output tables.
Absence Management Modes
Absence Management processes payees and elements by utilizing a very specific processing order. All the components of the system that you define, such as payees, elements, and rules, come together at the time an absence run is executed.
Think of Absence Management as having two primary modes:
Setup mode
During the setup mode, you define the various elements, rules, and other system configurations that make up your absence management system.
Processing mode
During the processing mode, Absence Management looks at all the setup information that you’ve defined, along with any data that you've entered, and processes it according to your specifications.
Note. The discussion in this section about the batch architecture process flow is a very high-level overview of the process. Each phase of the process is discussed in greater detail later in this PeopleBook.
Payee SelectionWhen you run an absence batch process, the first program that the system calls is the Service program. The Service program acts as the coordinator between the selection of payees to be processed and the calculation process. The Service program initiates the payee selection process. Once the payees are selected, the Service program passes control of the data that was created during the payee selection phase to the Calculation program.
This diagram shows how the Service program coordinates the payee selection and calculation phases:
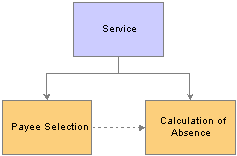
The Service program is the background processing starting point
Before you can process absences, you must identify the payees that are to be processed. In Absence Management, this is called payee selection or payee identification. Payee selection is required in absence processing.
The payee selection process is separate from the calculation process. No rules are defined for payee selection that is associated with an absence calculation. The payee selection phase of the process only identifies the payees and creates the data that is later passed on to the calculation phase.
The pay calendar acts as the controlling function that coordinates and defines the payee selection and calculation processes. The Payroll/Absence Run Control also controls payee selection.
On the calendar definition page, you indicate whether you want active payees or listed payees selected. If you select active payees, you are offered a number of other defining choices. If you select listed payees, you insert the employee ID numbers for the payees that you want to select.
The payee selection process also uses retroactive and period segmentation triggers. Retroactive triggers can cause other periods besides the current absence period to be processed for a particular payee. Period segmentation triggers can cause the absence period to be split into segments, thus producing multiple calculations.
The result of the payee selection process is the creation of Process Status (GP_PYE_PRC_STAT) and Segment Status (GP_PYE_SEG_STAT) records. A Process Stat record is created for each payee for each calendar (including retroactive processes). Segment Stat record is created for each payee for each segment in each calendar. The Process Stat and Segment Stat records are the storage places for the payee data that is related to the calendar that is being run. Essentially, the Process Stat and Segment Stat records list the payees and all the absence periods that are to be processed, including the current absence period and possible retroactive periods.
See Also
Understanding Absence Processing
Calculation (Technical)
Once payees have been selected, the Service program passes control to the calculation phase of the process. The calculation phase uses the data that is stored in the Process Stat and Segment Stat records as the beginning set of payee data.
The first step in calculating absences is to load process-level data into arrays, including data from sources such as pay entity, paygroup, eligibility group, calendar, and the process list. This system data is more static than the payee-specific data.
The calculation program processes each payee, using the Payee Process Stat records that were created during the payee selection phase. The program loads all the payee-level data into payee arrays, including data from table sources such as Job, Person, Compensation, and Overrides.
The process that loads the payee-level data into the arrays also refreshes its data or reset pointers to data between every absence run so that:
The correct effective-dated information is always used.
The correct year-to-date balances are always reflected.
At this stage, all the process-level and payee-level data is loaded into arrays, ready for processing.
Next, the calculation phase checks element eligibility.
The calculation program calls the Process List Manager program, which looks to the process list to determine which elements will be processed and in what order.
When the Process List Manager encounters an element to be processed, it calls the PIN Manager (a program that manages individual elements) to process each element that passed the element eligibility check earlier in the process. The PIN Manager references the PINV array during this process. The PINV array stores the results of all element resolutions during absence background processing. If the data stored in PINV indicates that an element has not already been resolved, the PIN Manager calls an element name number resolution program (a program that processes specific types of elements).
A separate array, called PINW, stores the accumulator data that is resolved during background processing.
Each PIN resolution program resolves a specific type of element. For example, one PIN resolution program might resolve absence elements while another might resolve formula elements. The PIN resolution program loads the element definition into memory. Then the program overrides the definition that is stored in memory with any payee overrides or positive input that is designated for that payee. If any elements are referenced in the element and overrides definitions that are now in memory, the program calls the PIN Manager to resolve them. Remember, an element can comprise other elements. During processing, this means that to resolve a single element, the system might need to resolve any number of other elements from which the primary element is created. The results of this process are used to calculate the values of other elements, and pass the values back to the PIN Manager, which writes them to the main value array (PINV).
Each element is resolved in a cyclical (or recursive) manner; that is, each element is resolved, and the data is stored (in PINV or PINW). Then the Process List Manager again looks to the process list to see what element is to be processed next, and the process is repeated.
When all calculations are complete for the absence run, the program writes the results to the appropriate output tables. First, the program references the PINV and PINW arrays and writes the results to the database. Then it references all positive input and writes the data to the positive input history records. Finally, the program generates deltas for any future retroactive processing.
This diagram shows the calculation phase of the batch process:
The calculation process
See Also
Managing Element Eligibility and Resolution
Pages Used to Set Up Process Lists
Arrays Used in Background Processing (Technical)In Absence Management background processing, arrays are used to store data. Arrays are temporary tables that COBOL programs use to store data during processing. Once processing is complete, the programs write the data from the temporary arrays to the appropriate output tables.
Occasionally you might need to modify the COBOL programs to accommodate a larger maximum array size than is defined in the programs that are delivered by the PeopleSoft system. If an array is too small (the data overflows the array), you get an error message, and the batch process fails. The error message (MSGID-ARRAY-OFLOW) identifies the array and the COBOL file where the array is defined. This guides you to the location in the designated file that might need modification.
Increasing the Occurs Count in Arrays
The table access programs allocate a specified, limited amount of memory space to store in a table array all the details of the absence management process tables that are typical for an absence run.
You can increase the maximum size of an array by increasing the occurs count in the appropriate table access program.
Note. This is the only COBOL modification that we detail because COBOL modifications to the delivered Absence Management programs are strongly discouraged.
For example, let’s look at a piece of unmodified code in GPCDPDM.CBL.
Below is an array and its related COUNT control field that prevents the program from aborting. When you make a modification, both highlighted numbers must be changed and kept in sync.
05 L-PMT-COUNT PIC 9999 VALUE 0 COMP. 88 L-PMT-COUNT-MAX VALUE 250. 05 L-PMT-DATA OCCURS 250 INDEXED BY PMT-IDX.
The assumption here is that there will never be more than 20 absences processed for a payee during any calendar run. If more than 20 absences were processed, the program would issue an error message (MSGID-ARRAY-OFLOW), and the absence management process would terminate.
While the system loads and refreshes this array once for each payee, the system refreshes other arrays for each absence, and loads and increments others throughout the entire process.
This type of modification is not difficult to deal with when you upgrade to a new Absence Management release, when PeopleSoft delivers a whole new set of source code. Then, you use your installation Compare utility to compare the new source that we send you with the old source.
The code in the example above is taken from the copy section called GPCDPDM.CBL. If you were to run the Compare utility, you would see that the new incoming source for GPCDPDM.CBL contains different values. You would probably decide to retain your change to the code.
Background Processing Output TablesThe goal of an absence background processing run is to produce a set of output tables, where your important background processing data results reside. Once you know the type of information that resides in the output tables that are generated by Absence Management, you can use those tables to produce reports and other data manipulations that are relevant to your organization's needs. This diagram shows the relationships between the background processing output tables:
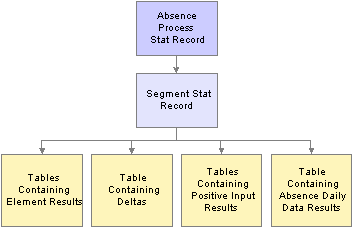
Relationships Between batch processing output tables
Tables Generated by Payee Selection Process
The payee selection process generates the following tables:
Pay Process Stat (status) record (GP_PYE_PRC_STAT)
There is one Pay Process Stat record for every EMPLID/EMPL_RCD combination per calendar.
There is a one-to-one/many relationship between the Pay Process Stat record and the Segment Stat record.
Segment Stat record (GP_PYE_SEG_STAT)
The Segment Stat record is a child of the Pay Process Stat record. There is one Segment Stat record for each gross to net within the calendar.
Tables Containing Element Results
The following tables contain element results:
Generated Positive Input (GP_GEN_PI_DATA)
Contains the results of earnings and deductions after background processing.
Other Elements (GP_RSLT_PIN)
Contains the results of miscellaneous element resolutions after background processing.
Table Containing Accumulator Results
The Accumulators table (GP_RSLT_ACUM) contains the results of accumulators after background processing.
The Deltas table (GP_RSLT_DELTA) contains deltas, which are the differences between two element results. This data is often important for processing retroactivity. This table is a child table to the Segment Stat (segment status) table (GP_PYE_SEG_STAT), which is a child of the Pay Process Stat table (GP_PYE_PRC_STAT).
Tables Containing Positive Input Results
The following table contains the absence daily data results.
Absence Daily Data (GP_RSLT_ABS)
Defining Installation Settings
When you install Absence Management, you select various settings and default values that are specific to your implementation.
This section discusses how to:
Indicate an Absence Management installation.
Define the default country.
Define Absence Management installation settings.
Define schedule settings and load dates.
Define country-level setup.
Pages Used to Define Installation Settings
|
Page Name |
Object Name |
Navigation |
Usage |
|
INSTALLATION_TBL1 |
Set Up HRMS, Install, Installation Table, Products |
Define the PeopleSoft applications installed. |
|
|
INSTALLATION_TBL3 |
Set Up HRMS, Install, Installation Table, Country Specific |
Define country-specific information. |
|
|
GP_INSTALLATION |
Set Up HRMS, Product Related, Global Payroll & Absence Mgmt, System Settings, Installation Settings |
Define installation settings that are unique to Absence Management. |
|
|
TL_INSTL_PUNCH |
Set Up HRMS, Product Related, Global Payroll & Absence Mgmt, System Settings, Installation Settings, Schedule Settings |
Define default settings for work schedules. |
|
|
TL_DATE_LOAD |
Click the Load Dates link on the Schedule Settings page. |
Load dates for use in resolving schedules. |
|
|
GP_COUNTRY |
Set Up HRMS, Product Related, Global Payroll & Absence Mgmt, System Settings, Countries |
Define country-level setup parameters. |
Indicating an Absence Management InstallationAccess the Products page and select the Absence Management Core check box.
If your organization also uses PeopleSoft Enterprise Payroll for North America or PeopleSoft Enterprise Payroll Interface, select the appropriate check box as well.
Note. To use the Absence Management application, the Global Payroll Core check box must be cleared.
See Also
Setting Up and Installing PeopleSoft HRMS
Defining the Default CountryAccess the Country Specific page.
Use the Country field to define the primary country in which your organization does business. This should be the country with the majority of your payees.
See Also
Setting Up and Installing PeopleSoft HRMS
Defining Absence Management Installation SettingsAccess the Installation Settings page.
Checkpoint intervals control how many employees are processed between database commits. You can select a different interval for the identify and calculation processing phases. Employees that are committed do not need to be recalculated if the run has to be restarted because of a technical error.
|
TL Feed Phase |
This field is currently not used. |
|
Progress Interval |
Controls how often the process writes a line to the process log stating how many employees have been processed. |
|
Months of Absence History |
Controls how long the system retains daily data for absences. |
|
Bundle PI on Output (bundle positive input on output) |
Selecting this check box causes the system to consolidate positive input during the absence process, when possible, so that you can send a single row of positive input to payroll. Positive input entries for the same absence event that share the same percent and rate are combined; the unit, amount, and base values are summed. Important! PeopleSoft recommends that you clear this field. Doing so enables Absence Management to send detailed information for each absence event to your payroll application. |
Defining Schedule Settings and Loading Dates
Access the Schedule Settings page.
|
Load Dates |
Click to access the Dates Table Load page where you can load the range of dates to be used in schedules. Dates from 1994 to 2014 are preloaded. You need only use this feature to load dates before or after this date range. |
|
Schedule Total Options |
Specify whether to include or exclude meal times, breaks, or both in the scheduled hours totals on schedule definitions, shift definitions, and the Manage Schedules page. Options are Exclude Meals and Breaks, Include Meals and Breaks, Include Meals, and Include Breaks. The default is Exclude Meals and Breaks. |
|
Schedule Resolution Options |
This field applies only if People Soft Enterprise Time and Labor is also installed. Specify how to resolve schedule changes. Select Take Last Schedule Update to have the system use the last update to resolve an employee's schedule, whether the update comes from a third-party, workforce scheduling system or an online override. Select Take Online Override to have the system look for an online schedule override to resolve the schedule for the day. The system does not look for changes from a third-party workforce scheduling system. |
Default Punch Pattern
Specify the default sequence for displaying punch types on the scheduling pages. You can also use the Grid Column Heading fields to modify the punch type labels that are to appear as column headings on the schedule pages.
See Also
Defining Country-Level SetupAccess the Countries page.
|
Net Pay Validation Formula |
This field is not applicable to Absence Management. |
|
Default Retroactive Method |
Values are Corrective and Forwarding. The only valid value for Absence Management is Corrective. |
|
On Conflict Retroactive Method |
Select which retroactive method, Corrective or Forwarding, to use when:
|
Store Non-Zero Delta Component
Select this check box in order for the system to store any delta amount or delta component that has a non-zero value, regardless of the setting on the Element Name (GP_PIN) page, Results group box for the element. Clear this check box in order for deltas to inherit the element's store option.
The following table provides an overview of how the system interprets the check box settings at different levels:
|
Element Store Option |
Country Delta Option |
Element is Stored |
Country is Stored |
|
ON |
ON |
YES |
YES |
|
ON |
OFF |
YES |
YES |
|
OFF |
ON |
NO |
YES |
|
OFF |
OFF |
NO |
NO |
Note. Additional information regarding retroactivity is discussed in detail in another chapter in this PeopleBook.
See Defining Retroactive Processing.
Use Current Results + Adjustment
The check boxes in this group box are not applicable to Absence Management.