Specifying Web Source General Settings
Access the General Settings page by selecting PeopleTools, Search Framework, Search Designer Activity Guide, Search Definition and selecting a Source Type of Web Source.
Use the General Settings page to specify the location of the files to be indexed as well as the crawler settings.
This example illustrates the fields and controls on the Web Source — General Settings page. You can find definitions for the fields and controls later on this page.
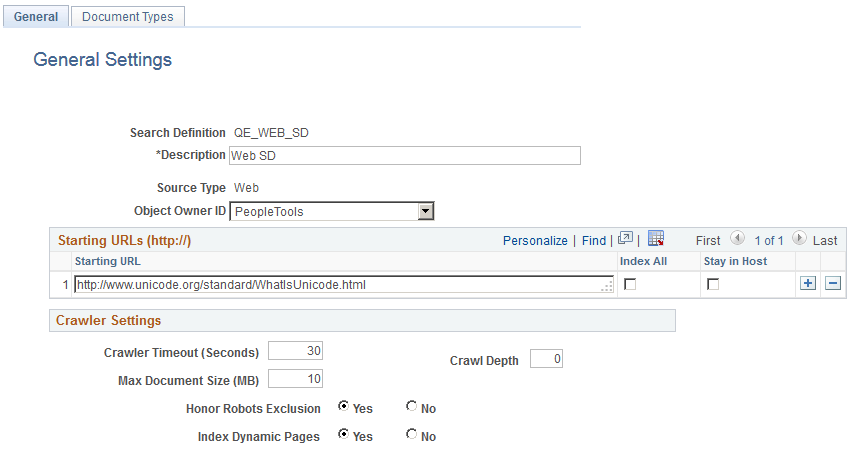
Field or Control |
Description |
|---|---|
Description |
Add a brief description to help identify the purpose of the search definition. |
Source Type |
Displays the type of search definition, such as Query, Web, File, and so on. |
Starting URLs |
Contains the URL of the web address. The search engine uses the URL as an entry point for starting to crawl a website. Important! Only HTTP URLs are supported. The starting URL's mentioned should be accessible without any user credentials. The search engine crawler will ignore web sites requiring login. |
Index All |
This will index all the URLs which are allowed to access by the search engine crawler. This will not limit crawling in to a specific domain or host. As the number of URLs to index increases, time required to complete indexing also increases. |
Stay in Host |
This will limit the indexing only to the specified host. For example, if you are indexing www.oracle.com and you select this option, you can index documents on www.oracle.com, but not on www.1.oracle.com. Important! If neither option is selected, then the system switches to Stay in Domain mode. In this mode, indexing will be limited to a single domain. For example if you are indexing www.oracle.com it will consider all URLs with in this domain, including www.1.oracle.com, but URLs from a different domain, such as www.yahoo.com, would not be indexed. |
Crawler Timeout |
Indicates the maximum allowed time to retrieve a file for crawling. |
Crawl Depth |
The number of nested links the crawler follows, with the initial URL, or home page, residing at a depth of 0. With a crawling depth of 1, the crawler also fetches any document linked to from the starting URL. With the crawling depth set to 2, the crawler fetches any document linked to from the starting URL (depth of 0), and also fetches any document linked to from the depth of 1, and so on. By adding a value for Crawl Depth, the system uses that value to enforce the crawling limit. If you enter no value, leaving the Crawl Depth blank, the system considers the crawling depth to be unlimited. As you increase the crawl depth, the content to be indexed can increase exponentially, which results in longer crawling durations. |
Max Document Size |
The maximum document size in megabytes that the system will crawl. Larger documents are not crawled. |
Honor Robots Exclusion |
Robot exclusion policies are set at web server and the web page level. The Honor Robots Exclusion setting controls whether the search engine recognizes or ignores the robot exclusion settings.
|
Index Dynamic Pages |
Controls whether search engine crawls and indexes dynamic pages. Typically, database applications serve dynamic pages, and the pages have a URL containing a question mark (?). The search engine considers URLs containing question marks dynamic pages.
|