
 Using State Records
Using State RecordsThis chapter discusses how to:
Use state records.
Set commits.
Reuse statements.
Use Bulk Insert.
Use set processing.
Using State RecordsThis section provides an overview of state records and discusses how to:
Share state records.
Choose a record type for state records.
Understanding State RecordsYou assign variables for your Application Engine program through state records, while sections, steps, and actions pass values to subsequent program steps through state records.
You can have any number of state records associated with a particular Application Engine program. However, only one record can be the default state record. You can specify both work (derived) and physical (SQL table) records to be used as state records. The only difference is that derived state records cannot have their values saved to the database at commit time, and so the values are lost during a restart. Therefore, PeopleSoft Application Engine erases the contents of derived state records at commit time if Restart is enabled for the current process.
A PeopleSoft Application Engine state record must have a process instance defined as the first field and the only key field, and the state record name must end with _AET.
Not all the database columns referenced in your program must be in the state record, just the columns that must be selected into memory so those values can be referenced in a subsequent program action. You may also want to include additional fields to hold pieces of dynamic SQL, to use as temporary flags, and so on.
PeopleSoft Application Engine supports long fields, unlike COBOL or Structured Query Reports (SQR). However, it allows only one long field per state record. You set a maximum size for the field in PeopleSoft Application Designer and make sure that the data space is compatible with the size of the field that you set.
PeopleSoft Application Engine also supports image fields and long text fields.
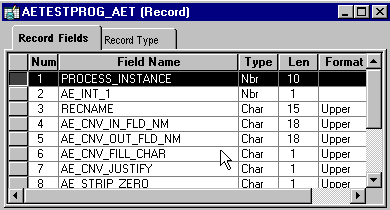
Sample state record
During batch processing, PeopleSoft Application Engine automatically performs all state record updates. When a program starts, it inserts a row into the state record that corresponds to the process instance assigned to that program run. PeopleSoft Application Engine updates the record whenever a commit operation occurs. When restart is enabled and a commit occurs, all state records that have been updated in memory are written to the database, except for derived state records, which are initialized instead.
After the program completes successfully, PeopleSoft Application Engine deletes the corresponding row in the state record. There is only one row in the state record for each process instance. Multiple programs can use the same state record, and each program has its own row based on the unique process instance key.
To set values in the state record, you use the %SELECT construct in a SQL statement or write PeopleCode that references the state field with the standard record.field notation. To reference fields in the state record, use the %BIND construct.
Sharing State RecordsState records can be used by multiple sections and by multiple programs. When you call a section in another program, any additional state records defined for that program (as in state records that are not already in use by the calling program) are initialized, even if the program has been called previously during the run. However, state records that are common to both programs retain their current values.
To reference variables that exist within a state record, use the following:
%BIND(fieldname)
Unless a specific record name is specified preceding the fieldname, %BIND references the default state record. To reference a state record other than the default, use the following:
%BIND(recordname.fieldname)
In the case of a called program or section, if the called program has its own default state record defined, then PeopleSoft Application Engine uses that default state record to resolve the %BIND(fieldname). Otherwise, the called program inherits the calling program's default state record. In theory, the called program does not require a state record if all the fields it needs for processing exist on the calling program’s state record.
For those state records that are shared between programs (during an external call section), any changes made by the called program remain when control returns to the calling program. Any subsequent actions in the calling program can access residual values left in the common state records by the called program. This can be useful to return output values or status to the calling program, yet it can also cause unforeseen errors.
Generally, a called program should not share state records with the caller unless you need to pass parameters between them. Most programs have their own set of state records unless a program calls another program that requires specific input or output variables. In that case, you must include the state record of the called program into the calling program’s state record list, and make sure to set the input values before issuing the call section.
Choosing a Record Type for State RecordsAs a general rule, to preserve state record field values across commits in your program, you should store those values in a state record with a record type of SQL Table. Only derived/work-type state records store values that don’t need to be accessed across commits. Derived/work records are, however, an excellent choice for temporary flags and dynamic SQL containers that are set and then referenced immediately. Because these values aren’t needed later, you don’t want to have to save them to the database at each commit. When you create your state record in PeopleSoft Application Designer, you should have an idea regarding how your state record will be used. With this information, you can select the appropriate record type to build.
With Application Engine programs, state records that are derived/work records function the same as SQL Table records. However, there is one notable distinction: unless you have disabled Restart, derived work records have their field values reinitialized after each commit. Therefore, unless you anticipate this behavior, you may encounter problems. One quick way to diagnose such a problem is to examine a trace. Typically, you see %BIND variables resolved to values prior to a commit, and then after the commit, they have no value.
This behavior is necessary to ensure consistency in the event of an abnormal termination and restart. During the restart, PeopleSoft Application Engine begins, or restarts, at the point of the last successful commit and restores the values of any state records with corresponding database tables. Derived/work records aren’t associated with a physical database table, and consequently they can’t be restored in the event of a restart.
Setting CommitsFor new Application Engine programs that you develop, by default, the commit values at the section and the step level are turned off. No commits occur during the program run, except for the implicit commit that occurs after the successful completion of the program.
It’s up to you to divide your program into logical units of work by setting commit points within your program. Typically, after PeopleSoft Application Engine completes a self-contained task, it might be a good time to commit. How often you apply commits affects how your program performs in the event of a restart. For set processing programs, commit early and often. For row-based processing, commit after every N iterations of the main fetch loop that drives the process.
If you have a step with a Do While, Do Until, or a Do Select action, you can set the frequency option, which drives your commit level. This enables you to set a commit at the step level that occurs after a specified number of iterations of your looping construct. Application Engine programs commit whenever they are instructed to do so, so you can enable the frequency option as well as have other individual commits inside of a loop.
The only restriction for batch runs occurs when you have restart enabled, and you are inside a Do Select action that is of the Select/Fetch type (instead of Re-select or Restartable). With Select/Fetch, all commits inside the loop are ignored, including the commit frequency if it's set.
The Restartable option is similar to Select/Fetch, except that you are implying to PeopleSoft Application Engine that your SQL is structured in such a way that it filters out rows that have been processed and committed. This enables a successful restart. One technique for accomplishing this is to have a processed flag that you check in the Where clause of the Do Select action, and you perform an update inside the loop (and before the commit) to set the flag to Y on each row that you fetch.
The commit logic is designed to perform a commit regardless of whether any database changes have occurred. The program commits as instructed, except when the program is restartable and at a point where a commit would affect restart integrity—inside a non-restartable Do Select action, for example.
When you set a step to commit by default, it means that the step's commit frequency is controlled by the section's auto commit setting. If the section is set to commit after every step, then the program commits. Otherwise, the program never commits unless the step is explicitly set to commit afterward.
Note. The Commit After, Later setting at the step level enables you to override the section setting if you don't want to commit after a particular step.
%TruncateTable Considerations
Some databases, such as Oracle, issue an implicit commit for a truncate command. If there were other pending (uncommitted) database changes, the results would differ if an abend occurred after the %TruncateTable. To ensure consistency and restart integrity, PeopleSoft Application Engine checks the following:
Whether there are pending changes when resolving a %TruncateTable.
If the program is at a point where a commit isn't allowed.
If either condition is true, PeopleSoft Application Engine issues delete from syntax instead.
Considerations with the No Rows Setting
The default for the No Rows setting (on the action) is Continue. This setting controls how your program responds when a statement returns no rows. In the case of %UpdateStats, you may want to set No Rows to Skip Step and thus skip the commit. For example, suppose you have a single Insert statement into a table, followed by an %UpdateStats. If the stats were current before the Insert statement, and the Insert statement affects no rows, then the %UpdateStats is unnecessary.
Reusing StatementsOne of the key performance features of PeopleSoft Application Engine is the ability to reuse SQL statements by dedicating a persistent cursor to that statement.
Unless you select the ReUse property for a SQL action, %BIND fields are substituted with literal values in the SQL statement. The database has to recompile the statement every time it is executed.
However, selecting ReUse converts any %BIND fields into real bind variables (:1, :2, and so on), enabling PeopleSoft Application Engine to compile the statement once, dedicate a cursor, and re-execute it with new data multiple times. This reduction in compile time can result in dramatic improvements to performance.
In addition, some databases have SQL statement caching. Every time they receive SQL, they compare it against their cache of previously executed statements to see if they have seen it before. If so, they can reuse the old query plan. This works only if the SQL text matches exactly. This is unlikely with literals instead of bind variables.
When using ReUse, keep the following items in mind:
ReUse is valid only for SQL actions.
Use ReUse only if you do not use bind variables for column names.
Use ReUse only if you have no %BIND variables in the Select list.
If the SQL is dynamic, as in you are using %BIND to resolve to a value other than a standard bind value, and the contents of the bind change each time the statement gets executed, then you can't enable ReUse.
In this situation, the SQL is different each time (at least from the database perspective) and therefore can't be reused.
If you use the NOQUOTES modifier inside %BIND, there is an implied STATIC.
For dynamic SQL substitution, the %BIND has a Char field and NOQUOTES to insert SQL rather than a literal value. If you enable ReUse, this means the value of the Char field gets substituted inline, instead of using a bind marker (as in :1, :2, and so on). The next time that the action executes, the SQL that it executes is the same as before, even if the value of a static bind has changed.
To prepare a reused statement from scratch, because one of the static binds has changed and the SQL has to reflect that, use %ClearCursor.
When making calls to an external section, program or library, the reusable cursors are retained upon exiting the program. However, if the calling program attempts to call another external section thereafter, the reusable cursors are discarded.
If you are running DB2 on OS/390 or AS/400, use the ReUse property only when you are not using %BINDS as operands of the same operator, as shown in the following example:
UPDATE PS_PO_WRK1 SET TAX = %BIND(STATE) + %BIND(FED)
This causes error -417. You can modify the SQL so that you can use ReUse successfully. Suppose your program contains the following SQL:
UPDATE PS_PO_WRK1 SET TAX = 0 WHERE %BIND(TAX_EXEMPT) = %BIND(TAX_STATUS)
If you modify it to resemble the following SQL, ReUse works:
UPDATE PS_PO_WRK1 SET TAX = 0 WHERE %BIND(TAX_EXEMPT, STATIC) = %BIND(TAX_STATUS)
Using Bulk InsertBy buffering rows to be inserted, some databases can get a considerable performance boost. PeopleSoft Application Engine offers this non-standard SQL enhancement on the following databases: Oracle, Microsoft SQLServer, and DB2. This feature is named Bulk Insert. For those database platforms that do not support bulk insert, this flag is ignored.
You should consider using this feature only when an Insert SQL statement is called multiple times in the absence of intervening Commit statements.
PeopleSoft Application Engine ignores the Bulk Insert setting in the following situations:
The SQL is not an Insert statement.
The SQL is other than an Insert/Values statement that inserts one row at a time.
For instance, the following statements are ignored: Insert/Select, Update, or Delete.
The SQL does not have a Values clause.
The SQL does not have a field list before the Values clause.
Note. Bulk Insert is also ignored when all three of the following conditions are true: the database platform is Oracle, the record contains and EFFDT field (effective date), and the record contains a mobile trigger. This is required because Oracle does not allow the reading of mutating tables in a row trigger.
In the situations where the Bulk Insert setting is ignored, PeopleSoft Application Engine still executes the SQL; it just doesn’t take advantage of the performance boost associated with Bulk Insert.
To prepare or flush a Bulk Insert statement because one of the static binds has changed and the SQL has to reflect that, use %ClearCursor. A flush also occurs automatically before each commit.
Using Set ProcessingThis section provides an overview of set processing and discusses how to:
Use set processing effectively.
Avoid row-by-row processing.
Use set processing examples.
Understanding Set ProcessingSet processing is an SQL technique used to process groups, or sets of rows, at one time rather than processing each row individually. Set processing enables you to apply a business rule directly on the data (preferably while it resides in a temporary table) in the database using an Update or Insert/Select statement. Most of the performance gain is because the processing occurs in the database instead of loading the data into the application program, processing it, and then inserting the results back into the database tables. Because the data never leaves the database with set processing (whether it remains in the same table), you effectively eliminate the network round trip and database API overhead.
Note. Because the updates in set processing occur within the database, use temporary tables to hold transient data while your program runs. Although temporary tables are not required for set processing, they are often essential to achieve optimum performance in your batch program.
Using Set Processing EffectivelyKeep the following in mind if you are developing new or upgrading older Application Engine programs to adhere to a set-based model.
Even if you're developing row-by-row programs with PeopleSoft Application Engine, you should be a SQL expert. With set-based programs, this is especially true. The following concepts are particularly important:
Group by and Having clauses.
Complex joins.
Subqueries (correlated and non-correlated).
Tools for your database to analyze complex SQL statements for performance analysis.
Typically, you use these SQL constructs to refine or filter the set to contain only the rows that meet particular criteria. Keep in mind that SQL is what you code with in PeopleSoft Application Engine, and Application Engine passes that SQL directly to the database, where it gets processed. If you have a complex SQL statement that works functionally, it may not necessarily perform well if it is not properly tuned.
Well-constructed, robust, and efficient Application Engine programs are usually the product of a detailed planning stage where loops, program flow, the use of temporary tables, sections, steps, and so on, are discussed.
In an ideal situation, address batch processing as a whole while you are designing the system. Sometimes, systems analysts and developers focus primarily on the online system during the database design, and then they consider the batch component within the existing database design. Set processing works best in an environment where the data models are optimized for set processing.
For example, you could have a separate staging table for new data that hasn’t been processed, rather than having numerous cases where existing rows in a table get updated. In set processing, it is much easier to process the data after moving it to a temporary table using an Insert or Select statement rather than just using an update. Avoid performing updates on real application tables, and try to perform your updates on temporary tables. To minimize updating real application tables, structure your data model to prevent that.
Another important consideration is keeping historical data separate from active transactions. After the lifecycle of given piece of transaction data is over, so that no more updates are possible, consider moving that data to an archive or history table and deleting it from the real transaction table. This keeps the number of rows in the table to a minimum, which improves performance for queries and updates to your active data.
Although temporary tables are not required for set processing, well-designed temporary tables complement your set-based program in a variety of ways.
Creating temporary tables enables you to achieve one of the main objectives involved with set based processing—the processing remains on the database server. By storing transient data in temporary tables, you avoid the situation where the batch program fetches the data, row by row, and runs the business rule, processes the data, and then passes the updated data back to the database. If the program were running on the client, you encounter performance issues due to the network roundtrip and the diminished processing speed of a client compared to the database platform.
Your temporary tables should be designed to accomplish the following:
Hold transaction data for the current run or iteration of your program.
Contain only those rows of data affected by the business rule.
Present key information in a denormalized, or flattened, form, which provides the most efficient processing.
Switch the keys for rows coming from the master tables if needed.
A transaction may use a different key than what appears on the master tables.
The most efficient temporary tables store data in denormalized form. Because most programs need to access data that resides in multiple tables, it is more sensible to consolidate all of the affected and related data into one table, the temporary table. It’s much more efficient for the program to run directly against the flattened temporary table rather than relying on the system to materialize complex joins and views to retrieve or update necessary data for each transaction.
If your program requires the use of a complex view to process transactions, then resolve the view into a temporary table for your program to run against. Each join or view that needs to materialize for each transaction consumes system resources and affects performance. In this approach, the system applies the join or view once (during the filtering process), populates the temporary table with the necessary information that the program needs to complete the transaction, and then runs the program against the temporary table as needed.
For example, consider the following situation:
A program needs to update 10,000 rows on the Customer table, which contains 100,000 rows of data. The Customer table is keyed by setID. To complete the transaction, the program references data that resides on a related table called PS_SET_CNTRL_REC. PS_SET_CNTRL_REC is used to associate setID and BUSINESS_UNIT values. The transaction is keyed by BUSINESS_UNIT.
Given that set of circumstances, the most efficient processing method would be similar to the following:
Isolate affected or necessary data from both tables, and insert that into the temporary table.
Now, instead of dealing with a 10,000-row Customer table and a join to a related table, the program faces a 10,000-row temporary table that contains all of the required data to join directly to the transaction data, which can also be in a temporary table. If all necessary columns reside on the temporary tables, the program can modify all the rows at once in a simple Update statement.
This example presents two different uses of temporary tables. In one situation, the temporary table is designed to hold setup/control data in a modified form. In the other situation, the temporary table is designed to hold transaction data in a denormalized form, perhaps with additional work columns to hold intermediate calculations.
Make sure the data appears in a denormalized form for optimum processing.
Because the transaction is keyed by BUSINESS_UNIT, the temporary table that holds the control data should also be keyed by BUSINESS_UNIT.
In this case, the table that holds the control data is the Customer table.
Avoiding Row-by-Row ProcessingA set-based program is not an all-or-nothing situation. There are some rules that call for row-by-row processing, but these rules are the exception. However, you can have a row-by-row component within a mostly set-based program.
For example, suppose your program contains five rules that you'll run against your data. Four of those rules lend themselves well to a set-based approach, while the fifth requires a row-by-row process. In this situation, run the four set-based steps or rules first, and then run the row-by-row portion last to resolve the exceptions. Although it's not pure set-based processing, you still obtain better performance than if the entire program used a row-by-row approach.
When performing a row-by-row update, reduce the number of rows and the number of columns that you select to an absolute minimum to decrease the data transfer time.
For logic that cannot be coded entirely in set, try to process most of the transactions in set, and process only the exceptions in a row-by-row loop. A good example of an exception is the sequence numbering of detail lines within a transaction, when most transactions have only a single detail line. You can set the sequence number on all the detail lines to 1 by default, in an initial set-based operation, then execute a Select statement to retrieve only the exceptions (duplicates) and update their sequence numbers to 2, 3, and so on.
Avoid the tendency to expand row-by-row processing for more than what is necessary. For example, just because you’re touching all of the rows of a given table in a specific row-based process, it doesn’t mean that you gain in efficiency by running the rest of your logic on that table in a row-based manner.
When updating a table, it’s OK to add another column to be set in the Update statement. However, do not add another SQL statement to your loop just because your program happens to be looping. If you can apply that SQL in a set-based manner, in most cases, you achieve better performance with a set-based SQL statement outside the loop.
The rest of this section describes techniques for avoiding row-by-row processing and enhancing performance.
Using SQL, filter the set to contain only those rows that are affected or meet the criteria and then run the rule on them. Use the Where clause to minimize the number of rows to reflect only the set of affected rows.
Use a two-pass approach, wherein the first pass runs a rule on all of the rows, and the second pass resolves any rows that are exceptions to the rule. For instance, bypass exceptions to the rule during the first pass, and then address the exceptions individually in a row-by-row manner.
Divide sets into distinct groups, and then run the appropriate rules or logic against each set in parallel processes. For example, in terms of employee data, you could split the population into distinct sets of "hourly" and "salary," and then you could run the appropriate logic for each set in parallel.
Flatten your temporary tables. The best temporary tables are denormalized and follow a flat file model for improved transaction processing.
For example, payroll control data might be keyed by set ID and effective dates rather than by business unit and accounting date. Use the temporary table to denormalize the data, and switch the keys to business unit and accounting date. Afterwards, you can construct a straight join to the Time Clock table, keyed by business unit and date.
Note the following:
If you have a series of identical temporary tables, examine your refinement process.
Don’t attempt to accomplish a task that your database platform does not support, as in complex mathematics, non-standard SQL, and complex analytical modeling.
Use standard SQL for set processing.
Although subqueries are a useful tool for refining your set, make sure that you’re not using the same one multiple times.
If you are using the same subquery in more than one statement, you should probably have denormalized the query results into a temporary table. Identify the subqueries that appear frequently and, if possible, denormalize the queried data into a temporary table.
Using Set Processing ExamplesThe following sections each contain an example of set processing.
Payroll
In this example, suppose the payroll department needs to give a USD 1000 salary increase to everybody whose department made more than USD 50,000 profit. The following pseudocode enables you to compare the row-by-row and set-based approaches.
Row-by-Row:
declare A cursor for select dept_id from department where profit > 50000; open A; fetch A into p_dept_id while sql_status == OK update personnel set salary = (salary+1000) where dept_id = p_dept_id; fetch A into p_dept_id; end while; close A; free A;
Set-Based:
update personnel set salary = (salary + 1000) where exists (select ‘X’ from department where profit > 50000 and personnel.dept_id = department.dept_id)
Note. The set-based example employs a correlated subquery, which is important in set-based processing.
One technique to improve database performance is to use a temporary table to hold the results of a common subquery. Effective dating and setID indirection are common types of subqueries that you can replace with joins to temporary tables. With the joins in place, you can access the temporary table instead of doing the subquery multiple times. Not only do most databases prefer joins to subqueries, but if you combine multiple subqueries into a single join as well, the performance benefits can be significant.
In this setID indirection example, you see a join from a transaction table (keyed by BUSINESS_UNIT and ACCOUNTING_DT) to a setup table (keyed by SETID and EFFDT).
To accomplish this using a single SQL statement, you need to bring in PS_SET_CNTRL_REC to map the business unit to a corresponding setID. This is typically done in a subquery. You also need to bring in the setup table a second time in a subquery to get the effective date (MAX(EFFDT) <= ACCOUNTING_DT). If you have a series of similar statements, this can be a performance issue.
The alternative is to use a temporary table that is the equivalent of the setup table. The temporary table is keyed by BUSINESS_UNIT and ACCOUNTING_DT instead of SETID and EFFDT. You populate it initially by joining in your batch of transactions (presumably also a temporary table) once, as described previously, to get all the business units and accounting dates for this batch. From then on, your transaction and setup temporary tables have common keys, which allows a straight join with no subqueries.
For the example, the original setup table (PS_ITEM_ENTRY_TBL) is keyed by SETID, ENTRY_TYPE and EFFDT.
The denormalized temporary table version (PS_ITEM_ENTRY_TAO) is keyed by PROCESS_INSTANCE, BUSINESS_UNIT, ENTRY_TYPE and ACCOUNTING_DT, and carries the original keys (SETID and EFFDT) as simple attributes for joining to other related setup tables, as in PS_ITEM_LINES_TBL for this example.
If the program references the setup table in only one Insert/Select or Select statement, you wouldn't see increased performance by denormalizing the temporary table. But if several SQL statements are typically executed in a single run, all of which join in the same setup table with similar setID and effective date considerations, then the cost of populating the temporary table up front provides long-term advantages.
Original setup table version:
INSERT INTO PS_PG_PENDDST_TAO (...) SELECT . . . . . ( (I.ENTRY_AMT_BASE - I.VAT_AMT_BASE) * L.DST_LINE_MULTIPLR * L.DST_LINE_PERCENT / 100 ), ( (I.ENTRY_AMT - I.VAT_AMT) * L.DST_LINE_MULTIPLR * L.DST_LINE_PERCENT / 100 ), . . . . . FROM PS_PENDING_ITEM I, PS_PG_REQUEST_TAO R, PS_ITEM_LINES_TBL L, PS_ITEM_ENTRY_TBL E, PS_SET_CNTRL_REC S, PS_BUS_UNIT_TBL_AR B . . . . . WHERE AND L.ENTRY_REASON = I.ENTRY_REASON AND L.SETID = E.SETID AND L.ENTRY_TYPE = E.ENTRY_TYPE AND L.EFFDT = E.EFFDT . . . . . AND E.EFF_STATUS = 'A' AND S.RECNAME = 'ITEM_ENTRY_TBL' AND S.SETID = E.SETID AND S.SETCNTRLVALUE = I.BUSINESS_UNIT AND E.ENTRY_TYPE = I.ENTRY_TYPE AND E.EFFDT = (SELECT MAX(EFFDT) FROM PS_ITEM_ENTRY_TBL Z WHERE Z.SETID = E.SETID AND Z.ENTRY_TYPE = E.ENTRY_TYPE AND Z.EFF_STATUS = 'A' AND Z.EFFDT <= I.ACCOUNTING_DT ) AND B.BUSINESS_UNIT = I.BUSINESS_UNIT /
Denormalized temporary table version:
INSERT INTO PS_ITEM_ENTRY_TAO . . . . . SELECT DISTINCT %BIND(PROCESS_INSTANCE), I.BUSINESS_UNIT, I.ACCOUNTING_DT, E.ENTRY_TYPE... . . . FROM PS_PENDING_ITEM I, PS_PG_REQUEST_TAO R, PS_ITEM_ENTRY_TBL E, PS_SET_CNTRL_REC S, PS_BUS_UNIT_TBL_AR B WHERE R.PROCESS_INSTANCE = %BIND(PROCESS_INSTANCE) AND R.PGG_GROUP_TYPE = 'B' AND I.POSTED_FLAG = 'N' AND R.GROUP_BU = I.GROUP_BU AND R.GROUP_ID = I.GROUP_ID AND E.EFF_STATUS = 'A' AND S.RECNAME = 'ITEM_ENTRY_TBL' AND S.SETID = E.SETID AND S.SETCNTRLVALUE = I.BUSINESS_UNIT AND E.ENTRY_TYPE = I.ENTRY_TYPE AND E.EFFDT = ( SELECT MAX(EFFDT) FROM PS_ITEM_ENTRY_TBL Z WHERE Z.SETID = E.SETID AND Z.ENTRY_TYPE = E.ENTRY_TYPE AND Z.EFF_STATUS = 'A' AND Z.EFFDT <= I.ACCOUNTING_DT ) AND B.BUSINESS_UNIT = I.BUSINESS_UNIT / INSERT INTO PS_PG_PENDDST_TAO (...) SELECT ... ( (I.ENTRY_AMT_BASE - I.VAT_AMT_BASE) * L.DST_LINE_MULTIPLR * L.DST_LINE_PERCENT / 100 ), ( (I.ENTRY_AMT - I.VAT_AMT) * L.DST_LINE_MULTIPLR * L.DST_LINE_PERCENT / 100 ), . . . . . FROM PS_PENDING_ITEM I, PS_PG_REQUEST_TAO R, PS_ITEM_LINES_TBL L, PS_ITEM_ENTRY_TAO E . . . . . WHERE . . . . . AND L.ENTRY_REASON = I.ENTRY_REASON AND L.SETID = E.SETID AND L.ENTRY_TYPE = E.ENTRY_TYPE AND L.EFFDT = E.EFFDT . . . . . AND E.BUSINESS_UNIT = I.BUSINESS_UNIT AND E.ACCOUNTING_DT = I.ACCOUNTING_DT AND E.ENTRY_TYPE = I.ENTRY_TYPE /
Set processing does not behave the same on every database platform. On some platforms, set processing can encounter performance breakdowns. Some platforms do not optimize update statements that include subqueries.
For example, environments that are accustomed to updates with subqueries get all the qualifying department IDs from the Department table, and then, using an index designed by an application developer, update the Personnel table. Other platforms read through every employee row in the Personnel table and query the Department table for each row.
On platforms where these types of updates are a problem, try adding some selectivity to the outer query. In the following example, examine the SQL in the Before section, and then notice how it is modified in the After section to run smoothly on all platforms. You can use this approach to work around platforms that have difficulty with updates that include subqueries.
Note. In general, set processing capabilities vary by database platform. The performance characteristics of each database platform differ with more complex SQL and set processing constructs. Some database platforms allow additional set processing constructs that enable you to process even more data in a set-based manner. If performance needs improvement, you must tailor or tune the SQL for your environment. You should be familiar with the capabilities and limitations of your database platform and can recognize, through tracing and performance results, the types of modifications you need to incorporate with the basic set processing constructs described.
Basic version:
UPDATE PS_REQ_LINE SET SOURCE_STATUS = 'I' WHERE EXISTS (SELECT 'X' FROM PS_PO_ITM_STG STG WHERE STG.PROCESS_INSTANCE =%BIND(PROCESS_INSTANCE) AND STG.PROCESS_INSTANCE =PS_REQ_LINE.PROCESS_INSTANCE AND STG.STAGE_STATUS = 'I' AND STG.BUSINESS_UNIT = PS_REQ_LINE.BUSINESS_UNIT AND STG.REQ_ID = PS_REQ_LINE.REQ_ID AND STG.REQ_LINE_NBR = PS_REQ_LINE.LINE_NBR)
Optimized for platform compatibility:
UPDATE PS_REQ_LINE SET SOURCE_STATUS = 'I' WHERE PROCESS_INSTANCE = %BIND(PROCESS_INSTANCE) AND EXISTS (SELECT 'X' FROM PS_PO_ITM_STG STG WHERE STG.PROCESS_INSTANCE =%BIND(PROCESS_INSTANCE) AND STG.PROCESS_INSTANCE =PS_REQ_LINE.PROCESS_INSTANCE AND STG.STAGE_STATUS = 'I' AND STG.BUSINESS_UNIT = PS_REQ_LINE.BUSINESS_UNIT AND STG.REQ_ID = PS_REQ_LINE.REQ_ID AND STG.REQ_LINE_NBR = PS_REQ_LINE.LINE_NBR)
Note. This example assumes that the transaction table (PS_REQ_LINE) has a PROCESS_INSTANCE column to lock rows that are in process. This is another example of designing your database with batch performance and set processing in mind.
This modification enables the system to limit its scan through PS_REQ_LINE to only those rows that the program is currently processing. At the same time, it enables a more set-friendly” environment to first scan the smaller staging table and then update the larger outer table.