 Understanding PeopleSoft Enterprise Portal Search
Understanding PeopleSoft Enterprise Portal SearchThis chapter provides overviews of:
PeopleSoft Enterprise Portal search.
PeopleSoft Enterprise Portal search infrastructure.
Search indexes for PeopleSoft applications.
Understanding PeopleSoft Enterprise Portal SearchPeopleSoft Enterprise Portal delivers enhanced search functionality beyond that of PeopleTools. The supporting technologies are the same, but additional features in PeopleSoft Enterprise Portal enable the incorporation of additional sources of content into search collections and additional features for end users.
PeopleSoft Enterprise Portal Search enables you to easily locate many different types of content within the portal. Users can perform a search from anywhere in the portal and retrieve links to documents, managed content, websites, and transactions, all in one place. Search can be performed across the entire portal or confined to a local site. Search results are filtered for security to ensure that users see only content to which they have access. Content categories are also retrieved along with the search results for managed content. Administrators control search index creation and security, as well as optional features such as multiple language searching, thesaurus, and content ratings integration.
The following diagram illustrates the PeopleSoft Enterprise Portal search architecture. The PeopleSoft Search API (application programming interface) connects the PeopleSoft portal technologies and the Verity technologies:
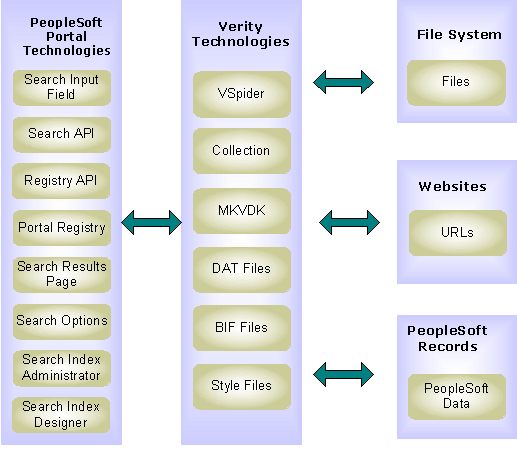
Key components of the PeopleSoft Enterprise Portal search architecture
The PeopleSoft Enterprise Portal search process uses the basic pieces that are included in the standard PeopleSoft portal search architecture. This documentation provides details about the components that are in addition to or different from the standard search architecture.
Note. The PeopleSoft system does not deliver a thesaurus file, but you can create your own file to use with PeopleSoft Enterprise Portal. On the Search Index Group page in PeopleSoft Enterprise Portal, you can select an option to indicate whether you want to use a thesaurus for each collection.
See Also
Verity Locale Configuration Guide v 6.1 for PeopleSoft, “Creating a Custom Thesaurus”
Understanding the Enterprise Portal Search InfrastructureThe new Enterprise Portal search infrastructure takes full advantage of the existing PeopleTools search API; it is a middle layer between that search API and the developer using the infrastructure. The new infrastructure provides the PeopleCode developer with these benefits:
Abstraction of the built-in logical collection swapping mechanism, which allows search collections to be built while in use, logically swapping the in-use collection once built successfully.
The swap is transparent to both the end-user and the developer using the search infrastructure.
Abstraction of index grouping, enabling the developer to simply specify index group name to use the appropriate indexes and filters associated with that index group.
Full serialization capabilities.
Because the new search infrastructure does not rely on the existing PeopleTools search API objects, which cannot be serialized at present, the new search infrastructure application classes can be used as Component or Global variables.
Pluggable search and build filters.
The new search infrastructure makes use of filters that can be used to apply security and formatting logic at search and build time, allowing full customization of the search results and index builds without direct modification to the base processes.
Once a search index is defined and built, it is added to a named index group. The first step in using the new infrastructure is to use the IndexService to obtain a list of all usable indexes for the current search request by index group name.
&indexService = create EO_PE_COMMON:Search:IndexService("INDEX_GROUP_NAME"); &indexService.addIndexFilter(create EO_PE_COMMON:Search:PermIndexFilter()); /* Check permissions */ &indexService.addIndexFilter(create EO_PE_COMMON:Search:BuiltIndexFilter()); /* Check exists */ &indexService.addIndexFilter(create EO_PE_COMMON:Search:SwapIndexFilter()); /* Check logical version */ &indexNames = &indexService.getIndexNamesAsString();
Upon instantiation, the desired index group name is specified, instructing the IndexService application class to retrieve information about all of the indexes included in that group. The addIndexFilter() method is used to install filters that will be responsible for determining if an included index should be used or not.
The PermIndexFilter index filter checks the permissions associated with the index in the group to ensure that the current user is authorized to search against that index.
The BuiltIndexFilter index filter ensures that the index in the group was built before it is used.
The SwapIndexFilter index filter makes sure that the index in the group is the current in-use index, and substitutes the name of the current in-use index if needed.
The IndexService does not need to be called if the developer simply wants to specify one or more hard-coded index names. If, however, the developer chooses not to use the IndexService class, it is that developer’s responsibility to perform any needed validation against those indexes before use.
Once a list of indexes is created, either with the IndexService.getIndexNamesAsString() method or as hard-coded by the developer, the QueryService class is used to perform the actual search (by eventually calling the existing PeopleTools search API).
&queryService = create EO_PE_COMMON:Search:QueryService("INDEX_GROUP_NAME"); &queryService.Indexes = &indexNamesString; &queryService.QueryText = &searchText; &queryService.RequestedFields = "TITLE, AUTHOR, SUMMARY, DESCRIPTION, PORTAL_NAME, INDEXNAME, OPRDEFNDESC"; &queryService.autoInstallQueryFilters(); /* Execute the search */ &queryService.performSearch();
Instantiated with the index group name, the QueryService class exists as a layer between the PeopleTools search API and the PeopleCode developer, providing a serializable search collection interface with many convenience methods to simplify the search request handling.
The autoInstallQueryFilters() method automatically installs any query filters specified by the portal administrator for this search index group. After the performSearch() method is called, first() and next() methods are used to extract post-filtered QueryResult objects from the QueryService object.
The QueryResult object stores the body of search results as simple name-value attributes pairs, and is the key to keeping the entire search infrastructure serializable.
&queryResult = &queryService.first(); While &queryResult <> Null &fieldLabel = &queryResult.getFieldValue("LABEL"); &fieldDescr = &queryResult.getFieldValue("DESCRIPTION"); &score = &queryResult.getFieldValue("SCORE"); &queryResult = &queryService.next(); End-While;
If extending and creating new query filters, the developer can define whatever new attribute names and values she or he wants.
Understanding Search Indexes for PeopleSoft ApplicationsA search index is a collection of files that is used during a search to quickly find documents of interest. The PeopleTools search engine is used to define and build search indexes for use with PeopleSoft software. The search engine contains utilities that enable you to administer indexes and create these three types of search indexes:
Record-based indexes.
HTTP spider indexes.
File system indexes.
For both HTTP spider and file system indexes, options are available to include or exclude certain documents based on file types and Multipurpose Internet Mail Extensions (MIME) types. The index building procedure is different for record-based indexes and the spider indexes. Typically, the index building procedure is carried out by the Build Search Indexes Application Engine process (EO_PE_IBLDR) job that is scheduled by using PeopleSoft Process Scheduler.
Record-based indexes are used to create indexes of data in PeopleSoft tables. For example, if the PeopleSoft application has a catalog record that has two fields, Description and PartID, you can create a record-based index to index the contents of the Description and PartID fields. After the index is created, you can use the PeopleCode search API to search this index.
HTTP spider indexes index a web repository by accessing the documents from a web server. You typically specify the starting URL. Then the indexer walks through all documents by following the document links and indexes the documents in that repository. You can control to what depth the indexer should traverse.
File system indexes are similar to HTTP spider indexes, except that the repository that is indexed is a file system. You typically specify the path to a folder or directory, then the indexer indexes all documents within that folder. HTTP spider indexes and file system indexes are sometimes collectively referred to as spider indexes. The indexer recognizes a wide variety of document formats, such as Word or Excel documents. Any document that is in an unknown format will be skipped by the indexer. You can control to what depth the indexer should traverse.
See Also
Enterprise PeopleTools 8.48 PeopleBook: System and Server Administration, "Building and Maintaining Search Indexes"